Using Google Chrome to Test Interface Techniques
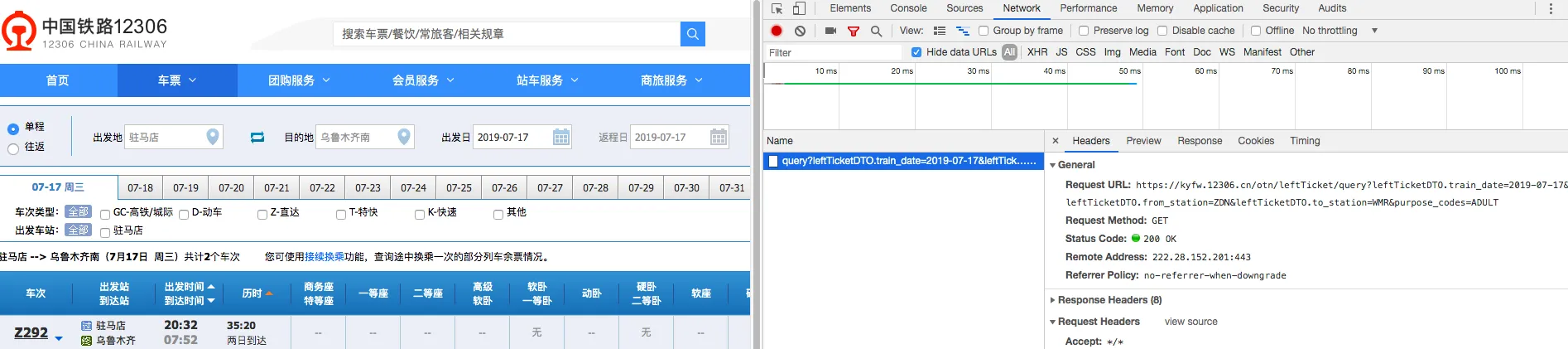
When writing web scrapers, it’s common to get frustrated and make mistakes due to manually editing headers and cookies. Here is a very convenient method to use Chrome’s built-in tools to generate Python requests.
Tools needed:
- Chrome browser
Steps
1. First, open the Network debugging tool in the browser. Here we take the example of querying ticket availability on 12306.
2. After querying, you will see our request. Using “copy as curl” you can get the curl version of the request.
curl is a Linux program used for downloading.
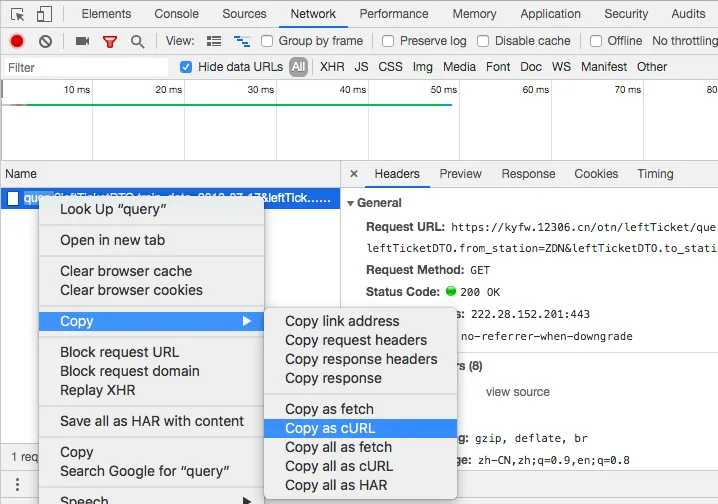
3. Convert to Python requests
You can use an existing tool for this, a web-based converter that can convert curl requests to multiple programming languages.
Website: https://curl.trillworks.com
Paste the curl request you copied in the previous step into the box, and on the right, you will get the Python version. For example, a query for tickets from Zhumadian to Urumqi.
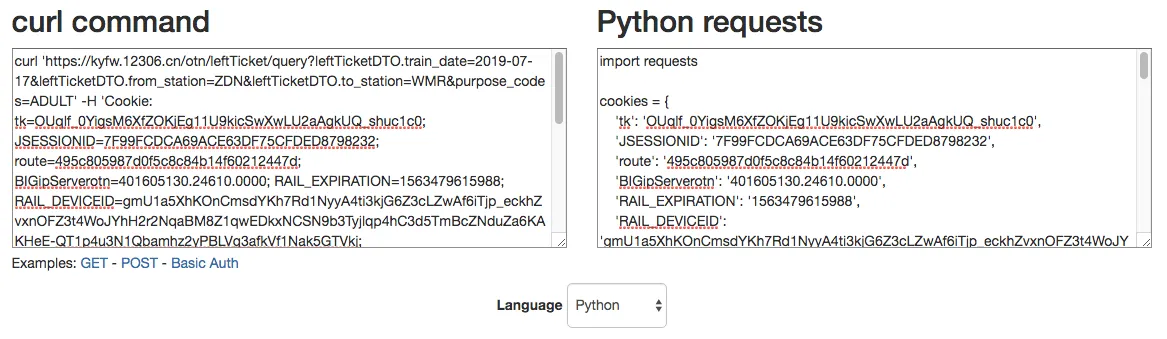
The final Python code looks like this:
import requests
cookies = {
'tk': 'OUqlf_0YigsM6XfZOKjEg11U9kicSwXwLU2aAgkUQ_shuc1c0',
'JSESSIONID': '7F99FCDCA69ACE63DF75CFDED8798232',
'route': '495c805987d0f5c8c84b14f60212447d',
'BIGipServerotn': '401605130.24610.0000',
'RAIL_EXPIRATION': '1563479615988',
'RAIL_DEVICEID': 'gmU1a5XhKOnCmsdYKh7Rd1NyyA4ti3kjG6Z3cLZwAf6iTjp_eckhZvxnOFZ3t4WoJYhH2r2NqaBM8Z1qwEDkxNCSN9b3Tyjlqp4hC3d5TmBcZNduZa6KAKHeE-QT1p4u3N1Qbamhz2yPBLVg3afkVf1Nak5GTVkj',
'BIGipServerpool_passport': '250413578.50215.0000',
'_jc_save_fromStation': '%u9A7B%u9A6C%u5E97%2CZDN',
'_jc_save_toStation': '%u4E4C%u9C81%u6728%u9F50%u5357%2CWMR',
'_jc_save_wfdc_flag': 'dc',
'_jc_save_fromDate': '2019-07-17',
'_jc_save_toDate': '2019-07-17',
}
headers = {
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Accept': '*/*',
'Cache-Control': 'no-cache',
'X-Requested-With': 'XMLHttpRequest',
'Connection': 'keep-alive',
'If-Modified-Since': '0',
'Referer': 'https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc&fs=%E9%A9%BB%E9%A9%AC%E5%BA%97,ZDN&ts=%E4%B9%8C%E9%B2%81%E6%9C%A8%E9%BD%90%u5357,WMR&date=2019-07-17&flag=N,N,Y',
}
params = (
('leftTicketDTO.train_date', '2019-07-17'),
('leftTicketDTO.from_station', 'ZDN'),
('leftTicketDTO.to_station', 'WMR'),
('purpose_codes', 'ADULT'),
)
response = requests.get('https://kyfw.12306.cn/otn/leftTicket/query', headers=headers, params=params, cookies=cookies)
# NB. Original query string below. It seems impossible to parse and
# reproduce query strings 100% accurately so the one below is given
# in case the reproduced version is not "correct".
# response = requests.get('https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2019-07-17&leftTicketDTO.from_station=ZDN&leftTicketDTO.to_station=WMR&purpose_codes=ADULT', headers=headers, cookies=cookies)
summary
This article introduces how to extract requests from the browser that can be used in Python requests. It is very convenient for web scrapers and avoids the complexity and errors of manually setting various parameters.
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/en/410.html
- 版权声明:本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。