Scraping Emojis with Scrapy and Building a Search Website Using Flask
Today I was chatting with my junior and he mentioned buying emoji packs from Taobao. I don’t have many emoji packs myself, but there are many emoji websites online. So why not scrape them and build my own emoji search site? This article uses Doutula as a demo site and explains the full process of scraping emoji packs using Scrapy and building a personal emoji search engine. The main steps are:
- Use Scrapy to scrape emoji packs and store them in MySQL
- Use Flask to build a search website
- Daily update: save images to local storage
Preparation: Anaconda Python 3
pip install scrapy
pip install flask
pip install pymysql
Scraping emoji packs using Scrapy and storing in MySQL
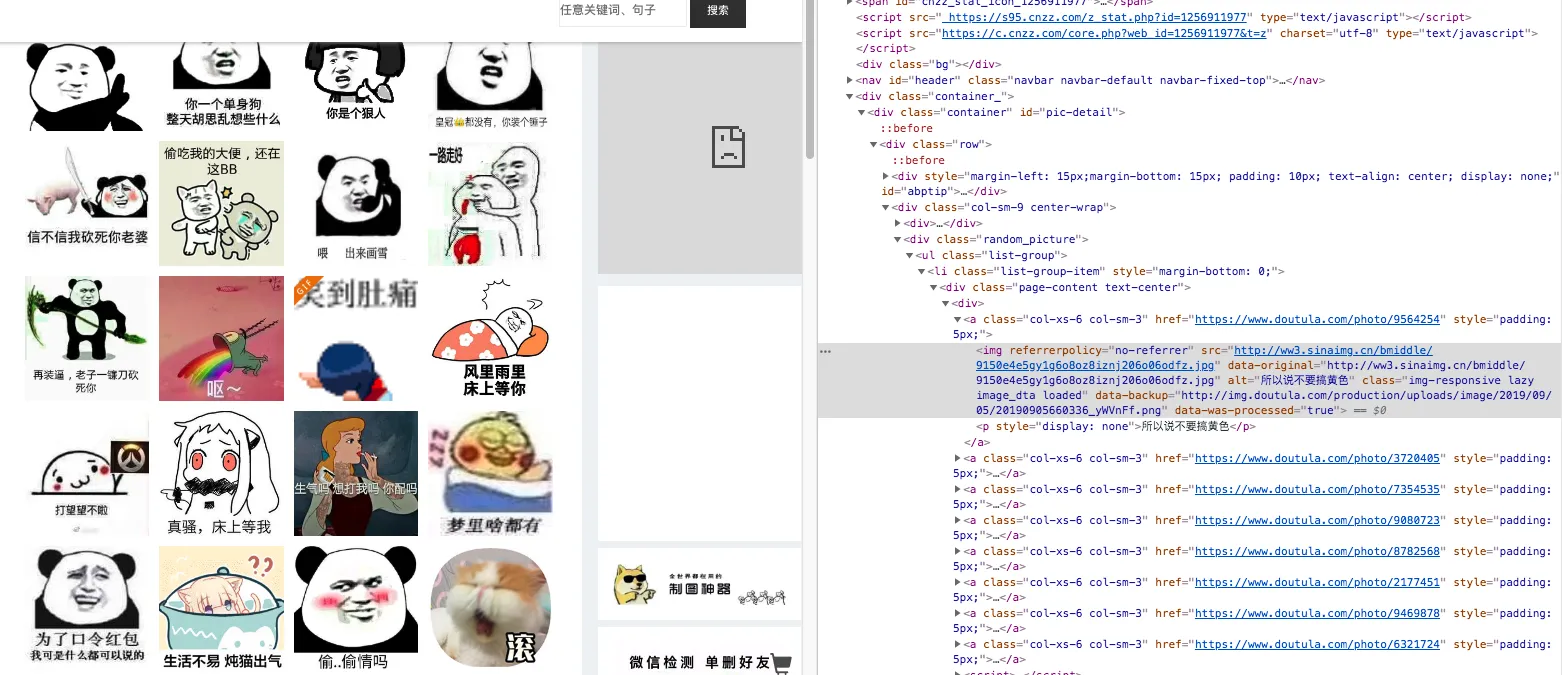
Inspect the website elements
Determine CSS selectors and MySQL table structure.
We can identify two key fields:
- Image URL, which is hosted on Sina, field name:
image_url - Emoji description, found in the
<p>element, field name:image_des - We also need a primary key:
id. When searching, we query the description to get the emoji URL for direct use.
Create the database and table
create database bqb;
use bqb;
DROP TABLE IF EXISTS `bqb_scrapy`;
CREATE TABLE `bqb_scrapy` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`image_url` varchar(100) NOT NULL,
`image_des` varchar(100) NOT NULL,
PRIMARY KEY (`id`),
KEY `image_url` (`image_url`)
) ENGINE=InnoDB AUTO_INCREMENT=187800 DEFAULT CHARSET=utf8mb4;
3 fields: auto-increment ID, image URL, and image description.
Write Scrapy spider
class DoutulaSpider(scrapy.Spider):
name = 'doutula'
allowed_domains = ['doutula.com']
start_urls = ['https://www.doutula.com/photo/list/']
for i in range(2,2773):
start_urls.append("https://www.doutula.com/photo/list/?page={}".format(i))
def parse(self, response):
item = {}
item['image_url'] = response.css("div.random_picture").css("a>img::attr(data-original)").extract()
item['image_des'] = response.css("div.random_picture").css("a>p::text").extract()
yield item
There are 2773 pages.
Use response.css("div.random_picture").css("a>img::attr(data-original)").extract() to get a list of image URLs, and
response.css("div.random_picture").css("a>p::text").extract() for descriptions.
Scrapy pipeline to save to MySQL
import pymysql
class BqbPipeline(object):
def open_spider(self,spider):
self.mysql_con = pymysql.connect('localhost', 'youruser', 'yourpass', 'bqb', autocommit=True)
self.cur = self.mysql_con.cursor()
def process_item(self, item, spider):
for i in range(len(item['image_url'])):
query = 'insert into bqb_scrapy(`image_url`,`image_des`) values("{}","{}");'.format(item['image_url'][i], item['image_des'][i])
self.cur.execute(query)
return item
def close_spider(self, spider):
self.mysql_con.close()
pymysql is used with autocommit to auto-save inserts.
Configure item.py and run spider
Update settings.py to enable the pipeline. In items.py, define fields:
import scrapy
class BqbItem(scrapy.Item):
image_url = scrapy.Field()
image_des = scrapy.Field()
Run the spider from the project root:
scrapy crawl doutula
You should see data being written rapidly to MySQL.
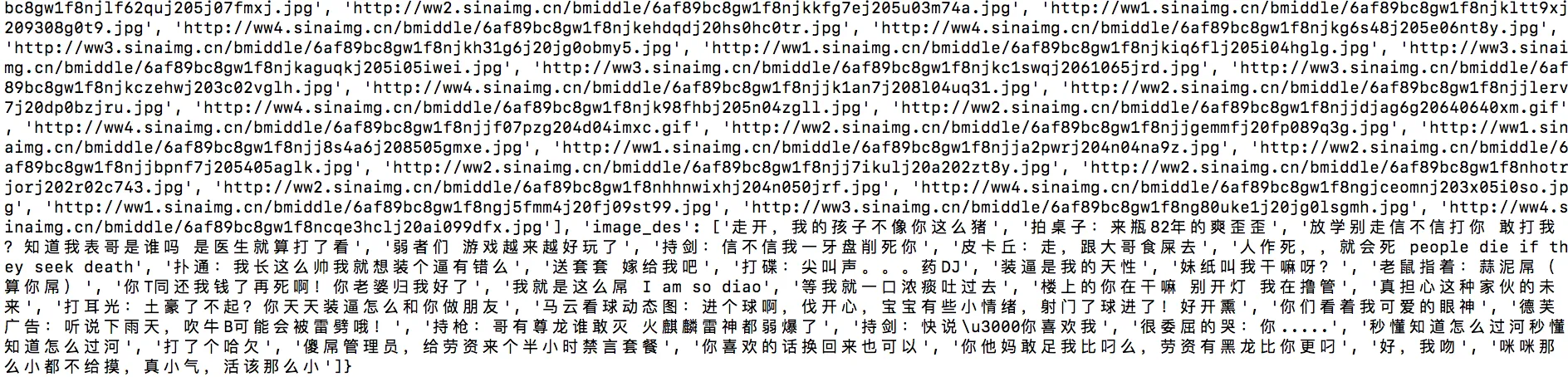
At this point, step one (scraping to MySQL) is complete.
Building the search website with Flask
We need three pages: homepage, search results, and 404.
Main app: bqb.py
import pymysql
from flask import Flask
from flask import request, render_template
app = Flask(__name__)
def db_execute(keyword):
conn = pymysql.connect('localhost', 'youruser', 'yourpass', 'bqb')
query = 'select image_url,image_des from bqb_scrapy where image_des like "%{}%" limit 1000;'.format(keyword)
cur = conn.cursor()
cur.execute(query)
res = cur.fetchall()
cur.close()
conn.close()
return res
@app.route('/', methods=['GET', 'POST'])
def search():
if request.method == 'GET':
return render_template('index.html')
elif request.method == 'POST':
keyword = request.form.get('keyword').strip()
items = db_execute(keyword)
if items != None:
return render_template('bqb.html', list=items)
else:
return 'not found'
else:
return render_template('404.html')
if __name__ == '__main__':
app.run(host='0.0.0.0', port=555)
Done. You can access via localhost:555. With nginx reverse proxy, the public domain is:
bqb.bobobk.com

Now you’ll never run out of emojis during chat battles.
Daily update: Save images to local storage
After running the site for a while, I noticed images failed to load. Likely due to hotlinking issues. So I decided to store images locally. Since the database holds hundreds of thousands of entries, putting everything into one folder is inefficient. I used a method that converts the file id to base-32 and splits it into 3 nested folders.
Export database to CSV
You can use phpMyAdmin or select into file directly:
use bqb;
select * from bqb_scrapy into outfile "bqb.csv";
Download images with Python + wget
import pandas as pd
import numpy as np
import os
def check_path(string1):
if os.path.exists(string1):
pass
else:
os.system("mkdir -p {}".format(string1))
def get_dir(num):
num_hex = hex(num)[2:].zfill(6)
return "/".join(["..", str(num_hex[:2]), str(num_hex[2:4])])
def request_file(url, filename):
if not os.path.exists(filename) or os.path.getsize(filename) == 0:
cmd = "wget {} -qO {}".format(url, filename)
os.system(cmd)
df = pd.read_csv("bqb.csv", header=None, usecols=range(4), names=["id", "url", "des", "bool"])
for i in df.index:
url = df["url"][i].replace("'", '')
fdir = df["id"][i]
path_dir = get_dir(fdir)
check_path(path_dir)
filename = path_dir + "/" + url.split("/")[-1]
request_file(url, filename)
This script uses a two-level folder system to avoid having too many files in one place. It checks for existing files before downloading to avoid re-downloading.
New version uses waterfall layout for better display.

Summary
This post walked through building a complete emoji search website:
- Scrape emojis from a public site with Scrapy
- Store in MySQL
- Use Flask to serve a search engine
- Handle image loading issues by downloading them locally
Due to free CDN limitations, only 20 images are shown per search. But now, with bqb.bobobk.com, you’ll always be the emoji king in chat!
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/en/471.html
- 版权声明:本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。