Python 日志排障实战:用 rg 和 uv 快速定位 Nginx 5xx 错误
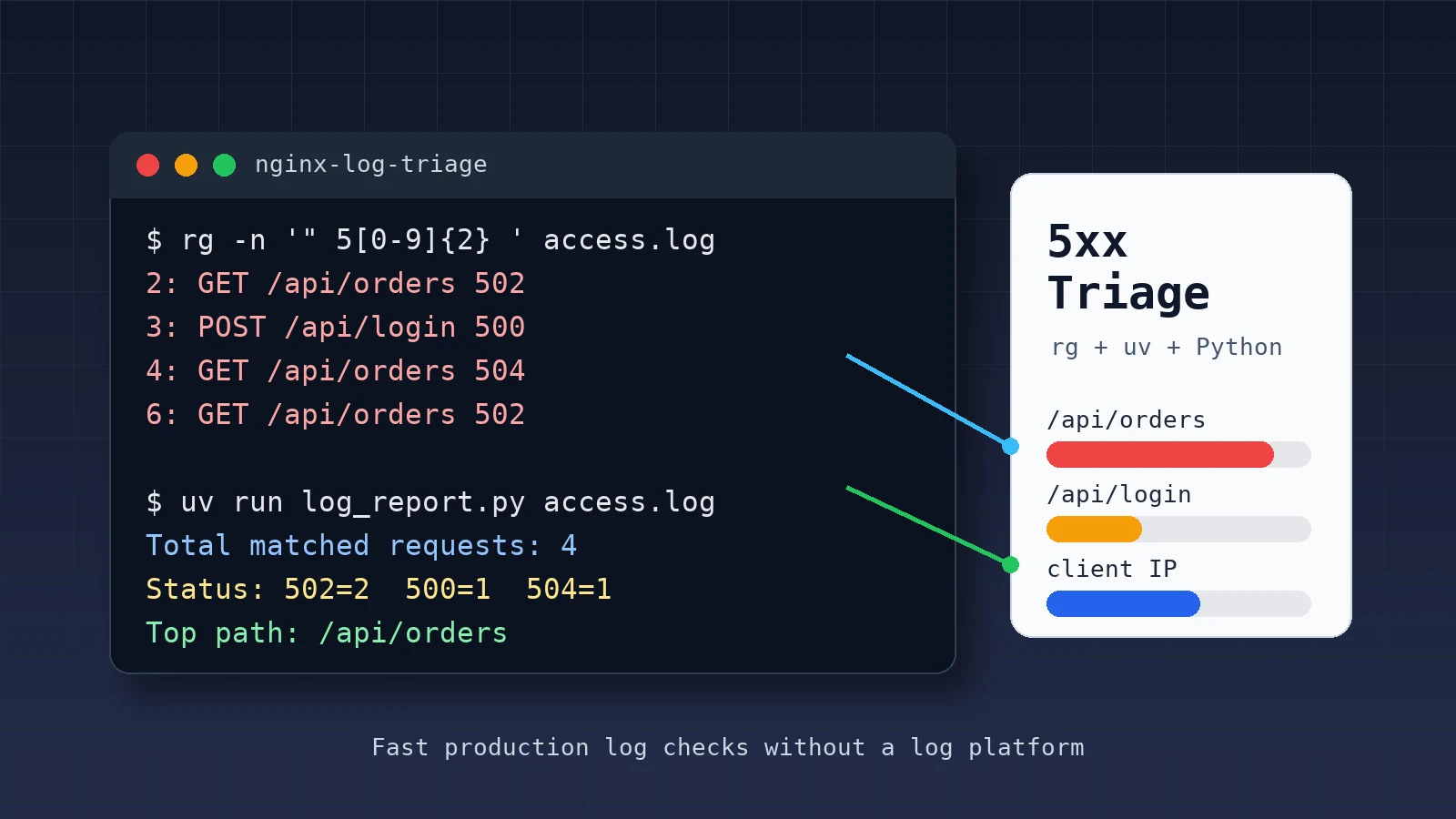
线上服务出问题时,最常见的第一步不是写复杂平台,而是先回答三个问题:什么时候开始报错、哪些 URL 报错最多、是不是集中在某些客户端或上游接口。
如果日志很大,直接用编辑器打开会很慢。更实用的方式是先用 rg 把可疑行筛出来,再用一个很小的 Python 脚本做统计。本文用 Nginx access log 做例子,搭一套可以复制到服务器上的排障流程。
完成后,你会得到:
- 一组常用
rg日志检索命令 - 一个
uv run即可执行的 Python 分析脚本 - 一份 5xx 状态码、URL 和 IP 排名摘要
- 常见报错的直接修复方法
适合什么场景
这套方法适合临时排障和轻量自动化:
- Nginx、Apache、应用 access log 体积较大
- 需要快速定位
500、502、503、504 - 还没有接入完整日志平台,或者日志平台查询不方便
- 想把一次性排查命令沉淀成可重复脚本
如果你已经有完善的 ELK、Loki 或云日志服务,仍然可以保留这个方法:服务器本地排查时,它通常更直接。
方法 1:先用 rg 缩小日志范围
先准备一个测试目录:
mkdir nginx-log-triage
cd nginx-log-triage
写入一份小型示例日志:
cat > access.log <<'EOF'
203.0.113.10 - - [03/Jun/2026:07:40:01 +0800] "GET / HTTP/1.1" 200 612 "-" "curl/8.0"
203.0.113.11 - - [03/Jun/2026:07:40:03 +0800] "GET /api/orders HTTP/1.1" 502 173 "-" "Mozilla/5.0"
203.0.113.12 - - [03/Jun/2026:07:40:08 +0800] "POST /api/login HTTP/1.1" 500 91 "-" "Mozilla/5.0"
203.0.113.11 - - [03/Jun/2026:07:41:15 +0800] "GET /api/orders HTTP/1.1" 504 173 "-" "Mozilla/5.0"
203.0.113.13 - - [03/Jun/2026:07:42:20 +0800] "GET /assets/app.css HTTP/1.1" 200 2048 "-" "Mozilla/5.0"
203.0.113.14 - - [03/Jun/2026:07:43:11 +0800] "GET /api/orders HTTP/1.1" 502 173 "-" "Mozilla/5.0"
EOF
查所有 5xx 行:
rg -n '" 5[0-9]{2} ' access.log
只看 502 和 504:
rg -n '" (502|504) ' access.log
查看匹配行前后各 1 行,方便看错误前后的请求:
rg -n -C 1 '" 5[0-9]{2} ' access.log
如果日志分散在多个文件里:
rg -n '" 5[0-9]{2} ' /var/log/nginx -g '*.log'
这一步的目标不是生成最终报告,而是快速确认:错误是否真实存在、集中在哪些文件、是否需要进一步统计。
方法 2:用 uv 运行 Python 统计脚本
rg 适合快速筛选,但如果要统计“哪个 URL 最多、哪个 IP 最多”,Python 会更稳。
创建一个脚本:
uv init --script log_report.py --python 3.12
把 log_report.py 改成下面这样:
# /// script
# requires-python = ">=3.12"
# ///
from __future__ import annotations
import argparse
import re
from collections import Counter
from pathlib import Path
LOG_PATTERN = re.compile(
r'(?P<ip>\S+) \S+ \S+ \[(?P<time>[^\]]+)\] '
r'"(?P<method>\S+) (?P<path>\S+) [^"]+" '
r'(?P<status>\d{3}) (?P<size>\S+)'
)
def iter_records(path: Path):
with path.open(encoding="utf-8", errors="replace") as file:
for line_number, line in enumerate(file, start=1):
match = LOG_PATTERN.search(line)
if not match:
continue
record = match.groupdict()
record["line"] = str(line_number)
yield record
def main() -> None:
parser = argparse.ArgumentParser(description="Summarize Nginx 5xx access log entries.")
parser.add_argument("log_file", type=Path)
parser.add_argument("--status", default="5", help="Status prefix, for example 5 or 50")
parser.add_argument("--top", type=int, default=5)
args = parser.parse_args()
status_count: Counter[str] = Counter()
path_count: Counter[str] = Counter()
ip_count: Counter[str] = Counter()
first_seen: str | None = None
last_seen: str | None = None
for record in iter_records(args.log_file):
status = record["status"]
if not status.startswith(args.status):
continue
status_count[status] += 1
path_count[record["path"]] += 1
ip_count[record["ip"]] += 1
first_seen = first_seen or record["time"]
last_seen = record["time"]
total = sum(status_count.values())
print(f"Total matched requests: {total}")
print(f"Time range: {first_seen or 'n/a'} -> {last_seen or 'n/a'}")
print("\nStatus:")
for status, count in status_count.most_common():
print(f" {status}: {count}")
print("\nTop paths:")
for path, count in path_count.most_common(args.top):
print(f" {count:>4} {path}")
print("\nTop client IPs:")
for ip, count in ip_count.most_common(args.top):
print(f" {count:>4} {ip}")
if __name__ == "__main__":
main()
运行脚本:
uv run log_report.py access.log
验证输出
正常输出类似下面这样:
Total matched requests: 4
Time range: 03/Jun/2026:07:40:03 +0800 -> 03/Jun/2026:07:43:11 +0800
Status:
502: 2
500: 1
504: 1
Top paths:
3 /api/orders
1 /api/login
Top client IPs:
2 203.0.113.11
1 203.0.113.12
1 203.0.113.14
这个结果已经能支持下一步排查:
/api/orders是最集中的错误 URL502比500更多,应该优先检查上游服务或反向代理- 错误集中在
07:40到07:43,可以继续对比应用日志和部署时间
方法 3:接入真实服务器日志
在服务器上可以先复制脚本,再对真实日志执行:
uv run log_report.py /var/log/nginx/access.log
只统计 502:
uv run log_report.py /var/log/nginx/access.log --status 502
多看几个排名:
uv run log_report.py /var/log/nginx/access.log --top 20
如果你只想分析最近追加的一部分日志,可以先用 tail 生成临时文件:
tail -n 20000 /var/log/nginx/access.log > recent-access.log
uv run log_report.py recent-access.log
这样做的好处是不会反复扫描完整大文件,排障时响应更快。
排障思路
拿到统计结果后,可以按下面顺序继续查:
500多:优先看应用错误日志、异常堆栈、数据库连接错误502多:检查 upstream 是否存活、端口是否正确、反向代理超时503多:检查限流、维护模式、服务池是否没有可用实例504多:检查慢查询、外部 API、上游响应时间和 Nginx timeout 配置
例如先查 Nginx error log:
rg -n "upstream|timeout|connect\\(\\) failed|refused" /var/log/nginx/error.log
再查应用日志里的同一时间段:
rg -n "07:4[0-3]|ERROR|Traceback|Exception" /path/to/app.log
常见问题
1. rg 找不到任何 5xx
先确认日志格式里状态码前后是否有空格。本文命令匹配的是 Nginx combined log 里这样的片段:
"GET /api/orders HTTP/1.1" 502 173
如果你的日志是 JSON,应该直接搜索 JSON 字段:
rg -n '"status":50[0-9]' access.jsonl
2. Python 脚本统计为 0
原因通常是日志格式不匹配。先打印一行真实日志:
head -n 1 access.log
如果字段顺序和示例不同,就需要调整 LOG_PATTERN。临时排障时也可以先用 rg 和 awk 解决,不必一开始就追求通用解析器。
3. 权限不够读取日志
如果当前用户不能读 /var/log/nginx/access.log,先检查权限:
ls -l /var/log/nginx/access.log
临时排查可以用:
sudo tail -n 20000 /var/log/nginx/access.log > recent-access.log
sudo chown "$USER":"$USER" recent-access.log
uv run log_report.py recent-access.log
4. 日志已经被压缩
rg 默认不直接搜索 .gz 内容。先用 zgrep 快速确认:
zgrep -n '" 5[0-9][0-9] ' /var/log/nginx/access.log.1.gz | head
需要做 Python 统计时,先解压到临时文件:
gzip -dc /var/log/nginx/access.log.1.gz > old-access.log
uv run log_report.py old-access.log
总结
排查日志时,不一定要先上复杂平台。rg 负责从大文件里快速定位可疑行,Python 负责把这些线索整理成状态码、URL 和 IP 排名,uv 让脚本可以在新机器上直接运行。
这套流程适合服务器临时排障,也适合沉淀成团队内部的小工具。下一次遇到 5xx 峰值时,先用这几条命令把问题范围缩小,再决定要查应用、数据库还是上游服务。
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/python-log-triage-rg-uv.html
- 版权声明:本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。