数据科学基础:常见概率分布及解释
概率分布对于统计至关重要,就像数据结构对于计算机科学一样。如果想真正理解建模、抽样、显著性检验和风险评估,概率分布几乎绕不过去。
很多时候,确实可以先直接调用 scikit-learn 或其他库完成一个分析流程,但如果不知道数据背后更像“计数”“等待时间”“是否发生”还是“均值附近波动”,模型选择和结果解释就很容易出问题。
概率分布有很多,但真正高频出现的并没有那么多。本文挑常见且实用的一批,按直观场景逐个解释。
定义:什么是概率分布
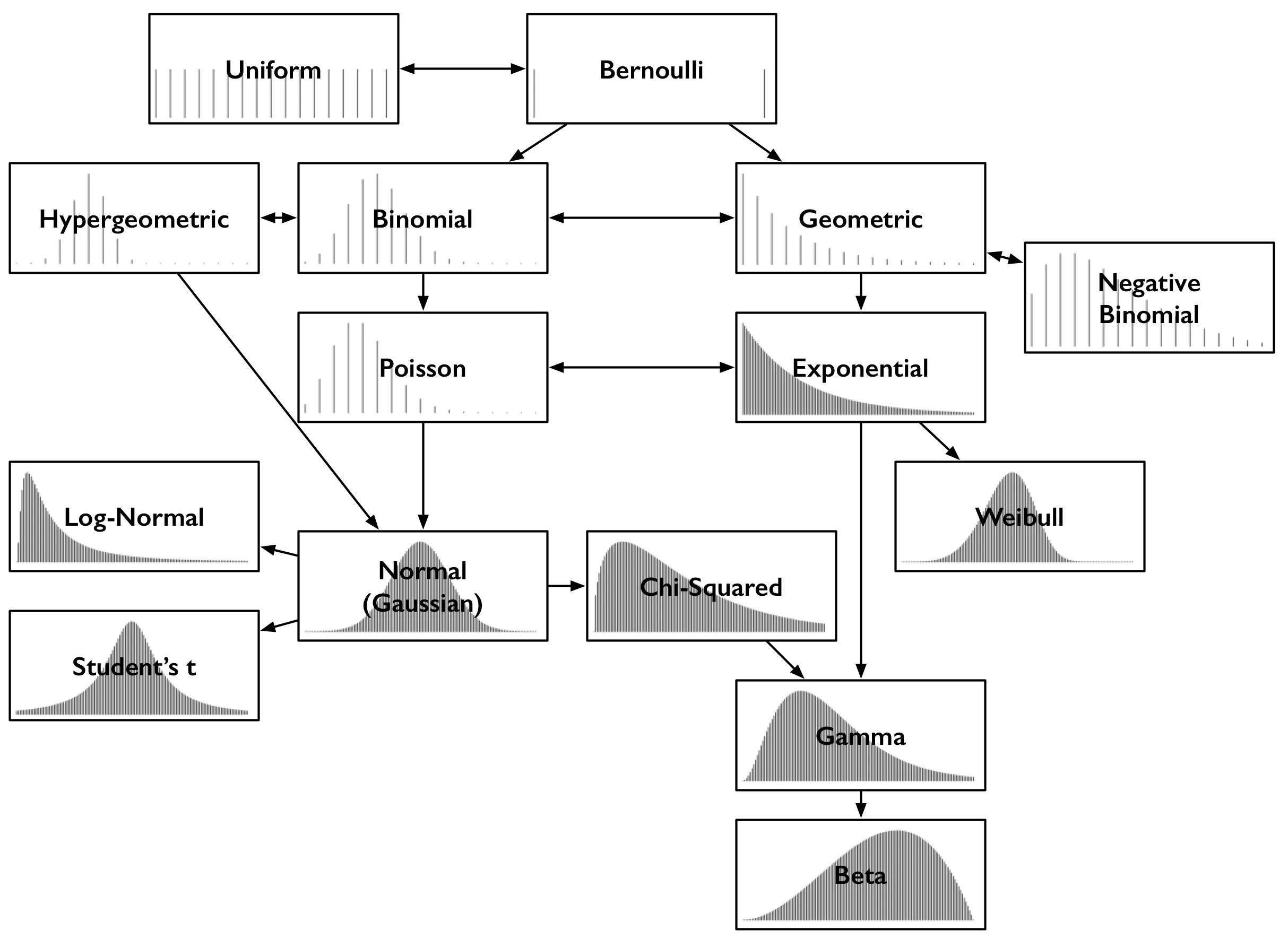
概率事情无时无刻不在发生:是否下雨,公共汽车到来时间,掷骰子等等。而后,事件的结果是:今天下了毛毛雨,公共汽车花了3分钟到达,骰子得到了3点。以前,我们只能谈论结果的可能性。概率分布描述了我们认为每个结果的概率是什么,有时候知道它比简单地显示哪个结果更有趣。它们有多种形状,但只有一个大小:分布中的概率总和为1。 例如,掷出一枚公平的硬币有两个结果:它落入正面或反面。(假设它不能降落在边缘或刚好在空中被鸟给叼走了),我们认为正面的几率为2分之一,即0.5。反面也是如此。这是翻转的两个结果的概率分布,如果您能理解这句话,那么您已经掌握了伯努利分布。 尽管有这各种各样的名称,但常见的概率分布类型主要就这么多,这么看下他们之间的关系图,以便于更好的理解各种概率分布之间的关系及演进。图片保存下来随时查看
每个分布都通过其概率密度函数(简称PDF)的示例进行了说明。因此,每个框中的x轴是一组可能的数字结果。y轴描述了结果的可能性概率。由于某些分布是离散的,其结果必须为0或1之类的整数。这些分布显示为稀疏线,就是每个结果对应一条线,其中线高是该横轴数字出现的概率。有些是连续的,其结果包含所有实数,这些显示为密集的曲线,在曲线的各个部分下方的区域给出了概率。线的高度和曲线下的面积的总和始终为1。
伯努利分布和均匀分布
抛硬币的伯努利分布,只有两个离散的结果,正面或者反面。从分布的角度上看,可以将其视为0和1上的分布,就是正面的概率和反面的概率。上面,这两种结果都有同等的可能性,这就是图中所示的情况。伯努利(Bernoulli)PDF具有两条高度相等的行,分别表示两端的两个相等的结果0和1。 伯努利分布可能代表不太一样的结果,例如抛不均匀硬币的结果。那么,正面的概率不是0.5,而是其他一些值p,而反面的概率是1- p。像许多分布一样,它实际上是由参数定义的一组分布,例如此处的p。当您想到“ Bernoulli ”时,只需考虑“(可能是不公平的)抛硬币。”这种概率分布情况。
接下来想象一下一个公平骰子,它有 6 个面,每个面的概率都一样,那么这就是均匀分布,其特征在于“每个结果一样可能”。
总结起来,伯努利分布只有两种情况:一个事件发生的概率为 p,另一个就是 1-p。均匀分布可以理解为“多个可能结果且各自概率相同”的情况。
二项式和超几何
二项式分布可以被认为是对以下伯努利分布多次重复事件结果的总和。投掷均匀的硬币20次; 有多少次出现正面?此计数是遵循二项式分布的结果。它的参数是n(试验次数)和p(“成功”概率)(此处为正面或1)。每次翻转都是伯努利分布的结果或试验。计算类似硬币翻转的事物的成功次数时,达到二项式分布,其中每个投掷都是独立事件,并且具有相同的成功概率。 或者,想象一个带有相等数量的白色和黑色球的黑盒子。闭上眼睛,摸一个球,观察它是否为黑色,然后放回去。重复。你摸了几次黑球?此计数也遵循二项式分布。 想象一下这种奇怪的情况是有道理的,因为它使解释超几何分布变得简单。如果取而代之的是球并没有被放回,那么这就是超几何分布。不可否认,它与二项式分布相似,但又不尽相同,因为成功的概率(摸到黑球)会随着球的摸出来而改变。如果球数相对于选择局数非常大,则分布相似,因为每次平局成功的机会变化较小。
总结下来就是二项分布是伯努利实验的重复放回实验,而超几何分布就是不放回的伯努利实验的事件结果的总和。
泊松分布
每分钟打给某热线电话的客户人数有多少?如果您将每秒视为伯努利试验,那么就是两种结果,即客户不打电话(0),客户打电话(1),那么这就是听起来是二项式的结果。但是,正如大家所知道的,两个人甚至数百人可以在同一秒内打电话。那么我们就需要假设1ms内热线拨打的概率,这时呼叫的可能性小得多,概率很低,但只要是两种可能性,成功概率为p,这还是伯努利试验的情况,只是概率p非常小而已。如果时间n无限小的话,这种极限他就是泊松分布。 像二项式分布一样,泊松分布是计数的分布-发生某事件的次数。它不是通过成功概率p和试验次数n来参数化,而是通过平均速率λ来参数化,在这个类比中,它只是np的常数。考虑到事件的连续发生率,当试图对一个事件进行计数时,您必须想到的是泊松分布。 当诸如一天卖多少个包子,数据包到达路由器,或者顾客到达商店的人数,或者诸如此类的时间段通过车辆的计数,这时候就是泊松分布的情况。
几何分布和负二项式分布
从最简单的伯努利试验就能得出另一种分布。抛硬币在第一次出现正面之前会出现多少次反面?也就是出现反面的次数遵循几何分布。像伯努利分布一样,它由p表示参数,即成功的概率。它的参数不是失败次数,结果是失败的次数。 如果二项分布是“成功了多少次?”,则几何分布是“直到成功已经有多少次失败了?”
而负二项分布这就是对几何分布是一个简单的概括和泛化。这是直到r次成功为止的失败次数,而不仅仅是1,几何分布就是1。因此,它也由r进行参数化。有时,它被描述为直到r个失败为止的成功次数。这个转换就是事件定义不同罢了,一种为正面概率,一种为反面概率,这些都是一样的。
指数分布和韦伯分布
返回热线电话人数:下一个客户要等多久?等待的时间的分布听起来像是几何形状的,因为没人呼叫的每一秒都像失败,直到最后有客户呼叫的那一秒。失败的次数就像没人呼叫的秒数,这差不多是等待下一次呼叫的等待时间,但是还远远不够。因为等待的时间始终以整秒计,而不能得到精确的时间。 前面一样,将几何分布朝着无限小的时间片分割到极限,并且它将最终有效。您将获得指数分布,它可以准确地描述通话之前的时间分布。这是一个连续分布,这是在这里第一次接听到电话,因为结果时间不必是整秒。像泊松分布一样,它由比率λ参数化。 二项式-几何关系,泊松分布的“每次发生多少个事件?”与指数分布的“直到发生一个事件需要多久?”相关。给定的事件其每次计数遵循泊松分布,则事件之间的时间遵循指数分布相同速率参数λ。讨论两个分布时,这两个分布之间的对应关系至关重要。 在考虑“事件发生之前的时间”,也许是“故障发生之前的时间”时,应该想到指数分布。实际上,这一点是如此重要,以至于存在更通用的分布来描述失效时间,这就是韦伯分布。当故障率恒定时,指数分布是适当的,而韦伯分布可以建模随时间增加(或减少)的故障率。指数分布只是一个特例。
正态,对数正态,t test和卡方
正态分布也称高斯分布,也许是最重要的。它的钟形结构可以很容易地识别。像自然对数e一样,它是一个奇怪的特殊实体,从看似简单的源头开始出现。按照相同的分布(任意分布)取一堆值,然后将它们求和。它们的和的分布遵循(大约)正态分布。总和越多,它们的总和分布与正态分布越匹配。(注意:必须是独立的良好的分布,仅最终会倾向于正态分布。)无论底层分布如何,都会趋近于正态分布。
这就是所谓的中心极限定理,您必须知道这就是所谓的极限定理和它的意思。
从这个意义上讲,它与所有分布有关。但是,它与事件发生的总和相关。伯努利试验的总和遵循二项式分布,并且随着试验次数的增加,该二项式分布变得更像正态分布。超几何分布也一样。泊松分布(二项式的一种极端形式)也随着速率参数的增加而接近正态分布。
任意随机变量的对数服从正态分布,那么这就是对数正态分布。换一种说法就是,任意正态分布的值取自然指数,那么这就是对数正态分布。再来一种说法,如果某分布的和服从正态分布,那么这个分布是正太分布。
t 分布是许多非统计学家在其他科学领域接触到的 t 检验背后的基础分布。它用于小样本、总体方差未知时,对正态总体均值进行推断,并且随着自由度增加会逐渐接近正态分布。t 分布的显著特征是尾部比正态分布更厚。
t 检验本身是方法,t 分布才是分布。小样本估计总体均值时,通常要先想到 t 分布;如果样本量足够大,或者总体方差已知,则通常更接近正态分布的使用场景。
卡方检验是一种统计量的分布在零假设成立时近似服从卡方分布的假设检验。在没有其他的限定条件或说明时,卡方检验一般指代的是皮尔森卡方检验。
如何快速判断该用哪一类分布
如果你在实际分析里拿到一组数据,不知道先想到哪种分布,可以先用下面这套最简单的判断法:
- 结果只有两种,比如“点击/不点击”“成功/失败”,先想到伯努利分布。
- 看的是重复实验里“成功了多少次”,先想到二项分布。
- 看的是单位时间内“发生了多少次”,先想到泊松分布。
- 看的是“等多久才发生一次”,先想到指数分布。
- 看的是“第一次成功前失败了几次”,先想到几何分布。
- 数据围绕均值左右波动、形状近似钟形,先想到正态分布。
- 小样本、总体方差未知、要估计均值,先想到 t 分布。
- 看的是分类频数是否和预期一致,通常会碰到卡方分布或卡方检验。
这不是严格证明,只是一个非常实用的第一反应框架。先把问题识别成“计数、等待时间、二元结果、连续波动”中的哪一类,分布选择通常就不会偏得太离谱。
总结
本文总结了统计学和数据科学里最常见的一批概率分布,以及它们各自最典型的使用场景。真正实战时,不一定要先推完整公式,但至少要先判断你的数据更像“是否发生”“发生几次”“等多久”还是“围绕均值波动”。
一旦把这个问题分清楚,后续无论是做建模、做检验,还是解释结果,都会顺很多。
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/712.html
- 版权声明:本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。