faceswap训练资源获取与处理
在上回faceswap深度学习AI实现视频换脸详解文章后,大家都已经学会了怎样通过训练模型来使用AI进行视频中人物脸部替换。但是现实中用来训练AI的图片资源的获取以及前期处理非常重要,如果没有良好的符合标准图片进行训练的话,也就无法获得良好的模型。
1.谷歌图片批量下载
作为一名程序员,自然不能说通过手动四处收集图片了,这里春江暮客将给大家介绍一款非常火的工具google-images-download,通过谷歌搜索自动下载所需图片,免去手动下载的烦恼。
直接使用pip安装即可
pip install google_images_download
程序安装好后使用下面命令搜索下载,这里以刘亦菲为例。
googleimagesdownload --keywords "刘亦菲" --size large
只下载大图。去掉size参数下载的图片会更多一点。
2.豆瓣图片批量下载
豆瓣电影里面的图片非常多而且是高清图片,是个非常合适的资源,这里我们使用scrapy批量下载。
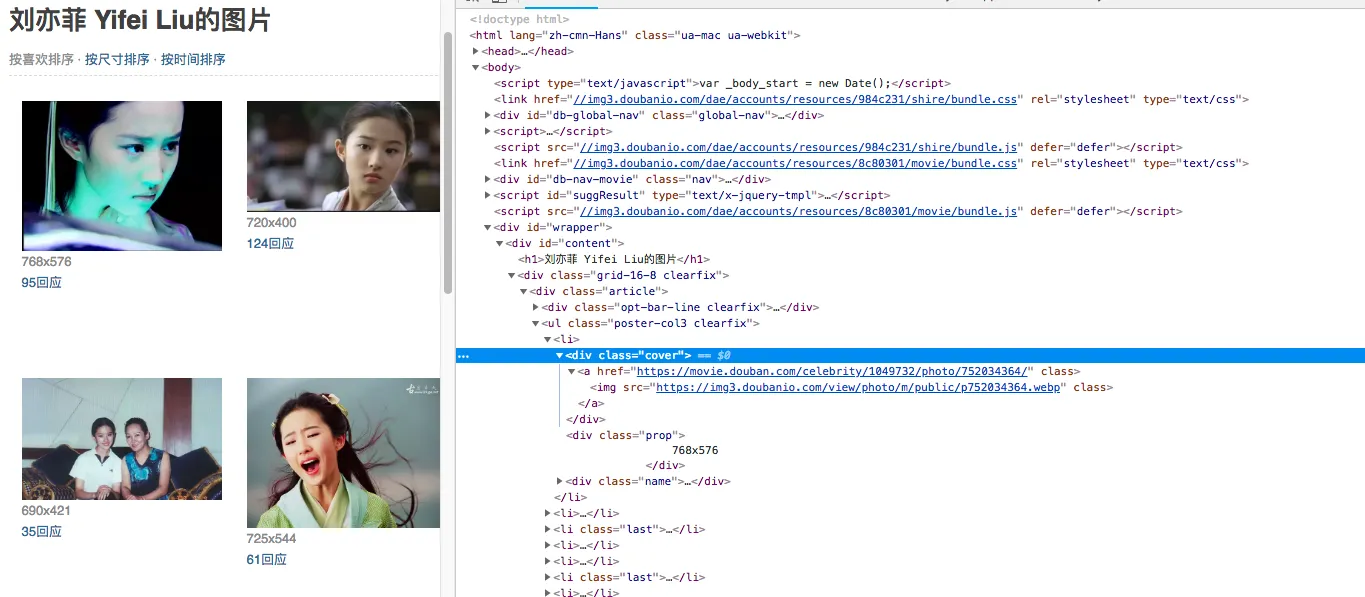
首先打开刘亦菲的图片页面,审查,用如下方式查看,可知图片url存在于cover标签下的a标签下的img的src属性中,使用css很方便就可以提取了。
Scrapy spider代码:
# -*- coding: utf-8 -*-
import scrapy
class LiuyifeiSpider(scrapy.Spider):
name = 'liuyifei'
allowed_domains = ['movie.douban.com']
start_urls = []#定义爬取的开始页面
for i in range(68):
start_urls.append("https://movie.douban.com/celebrity/1049732/photos/?type=C&start=%d&sortby=like&size=a&subtype=a" % (30*i))
# print(start_urls)
def parse(self, response):
pic_url = "\n".join(response.css("div.article").css("div.cover >a >img::attr(src)").extract()) ##这里css提取图片链接
yield {"pic_url":pic_url}
获得豆瓣上所有的关于刘亦菲的图片后就可以使用requests下载图片了。
# -*- coding: utf-8 -*-
import requests
import time
for i in open("piurl.txt").readlines():
picname = i.strip().split("/")[-1] #图片名
url = i.strip().replace("/m/","/l/")#链接替换
fw = open("liuyifei/"+picname,'wb')
fw.write(requests.get(url).content)
fw.close()
time.sleep(0.5)
为了获取高清的图片,把url中的参数替换成高清图片的链接。
3.提取面部图片用于训练
在通过豆瓣或者谷歌把主角的图片下载好后,就可以进行脸部的提取了,将图片放在一个文件下,进入上篇文章的目录进行主角面部特征的提取。
python faceswap.py extract -i original -o input
4.手动剔除不符合条件的图片
再用程序提取面部特征图片后,下一步就是最痛苦的手动筛选了。
这主要是因为下载的图片可能含有其他人物或者识别错误的情况,下载图片到本地一张一张过一遍就好了。
总结:
针对图片来源问题,这里推荐大家从豆瓣用scrapy下载喜欢的要替换的明星的图片,我这里选择刘亦菲,你也可以选择迪丽热巴,baby之类的,自由选择。
图片筛选非常重要,因为神经网络识别人物会识别多个脸部,所以手动筛选部分必不可少。
在收集到大量明星的图片集后,像给哪个明星的视频换脸就给哪个明星换脸了,哈哈哈,so happy。
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/271.html
- 版权声明:本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。