scrapy爬取字幕组今日更新影视-附源码
由于本人比较喜欢看美剧,字幕组的美剧资源更新又是非常快的,而本人scrapy爬虫写的也比较多,同时维护了一个小小的影视站给朋友下载,就想着能不能够用脚本实现每天的字幕组影视资源的更新与抓取,google后发现https://blog.csdn.net/lzw2016/article/details/80384481这篇博客比较详细的把接口信息什么的都分析好了,正好可以拿来实现自己的scrapy爬虫。伸手党直接跳到最后查看源码地址下载即可。
首先最总要的部分,spider爬虫
登录获取影视resource ID
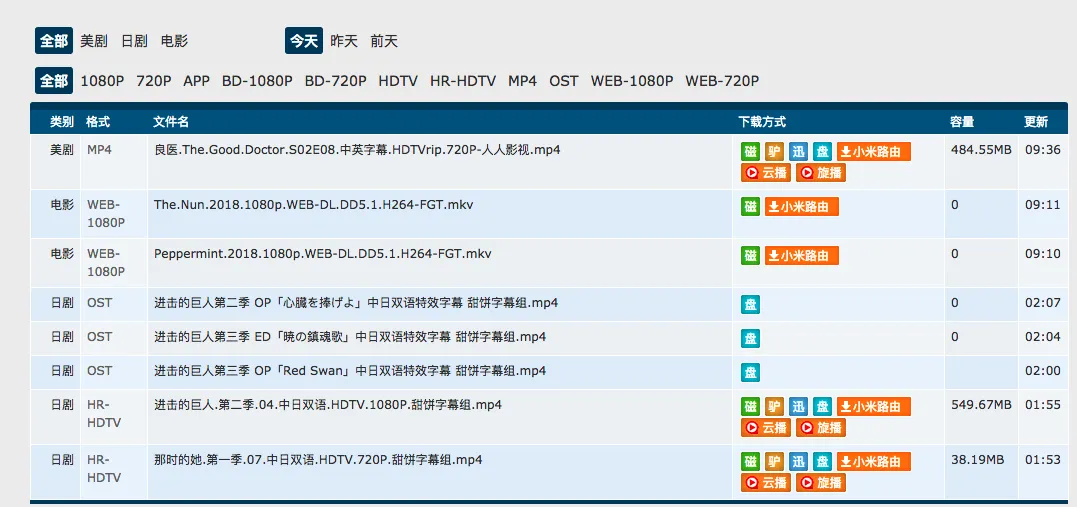
 从图片中可以看到,要获取今日更新影视,必须先登录,因此选择登录,这里我们直接使用python3的requests库的session部分就好了,相对python2来说的话,真的是方便了好多啊。
从图片中可以看到,要获取今日更新影视,必须先登录,因此选择登录,这里我们直接使用python3的requests库的session部分就好了,相对python2来说的话,真的是方便了好多啊。
def login_get_link(username,password):
print(username)
print(password)
loginurl='http://www.zimuzu.tv/User/Login/ajaxLogin'
surl='http://www.zimuzu.tv/today'
header={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Origin':'http://www.zimuzu.tv',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded',
}
data="account="+username+"&password="+password+"&remember=1"
# print(data)
session=requests.Session()
login=session.post(loginurl,data=data,headers=header)
print(login.json())
getstat=session.get(surl).text
m_new = re.findall(r'href="/resource/(\d{4,5})"',getstat)
m_new = list(set(m_new))
# print(m_new)
today_m = []
for i in m_new:
json_text = session.get("http://www.zimuzu.tv/resource/index_json/rid/%s/channel/tv" %i).text.replace("\\","")
try:
json_text = re.search(r'(zmz003.com/\w*?)"',json_text).group(1)
# print("success re:%s" % json_text)
today_m.append(json_text)
except:
# print("failure id:%s" % json_text)
pass
# print(today_m)
return today_m
登录后的页面
查看源代码,可以明显发现,更新内容是存在于<td><a href="/resource/36685"中的,所以这里直接采用python的正则表达式re.findall(r'href="/resource/(\d{4,5})"',getstat)就可以提取出来resource ID了。
登录获取影视resource ID
提取ID之后,我们直接使用json接口地址调用就可以了,调用方式是www.zimuzu.tv/resource/index_json/rid/%s/channel/tv,这里强调,因为版权问题,字幕组采用了只有登录才能查看下载资源地址,同时把地址放在了另外一个站点zmz003.com,而且是限时下载的(这招对有版权问题的站点很有借鉴作用0-0,当然还是提倡大家尊重版权)。因为我通过不同调用方式发现不管最后是tv还是movie其实影响的仅仅是其他的推荐影视,这里为了方便所有的调用都是直接采用tv的方式。再次查看源码可以发现直接使用正则表达式获取re.search(r'(zmz003.com/\w*?)"',json_text).group(1)。
影视下载地址爬取
在获取到真正的下载站地址后,就可以直接下载了,因为下载站和字幕组是分离的,这里并不需要登录。随便打开一个地址查看
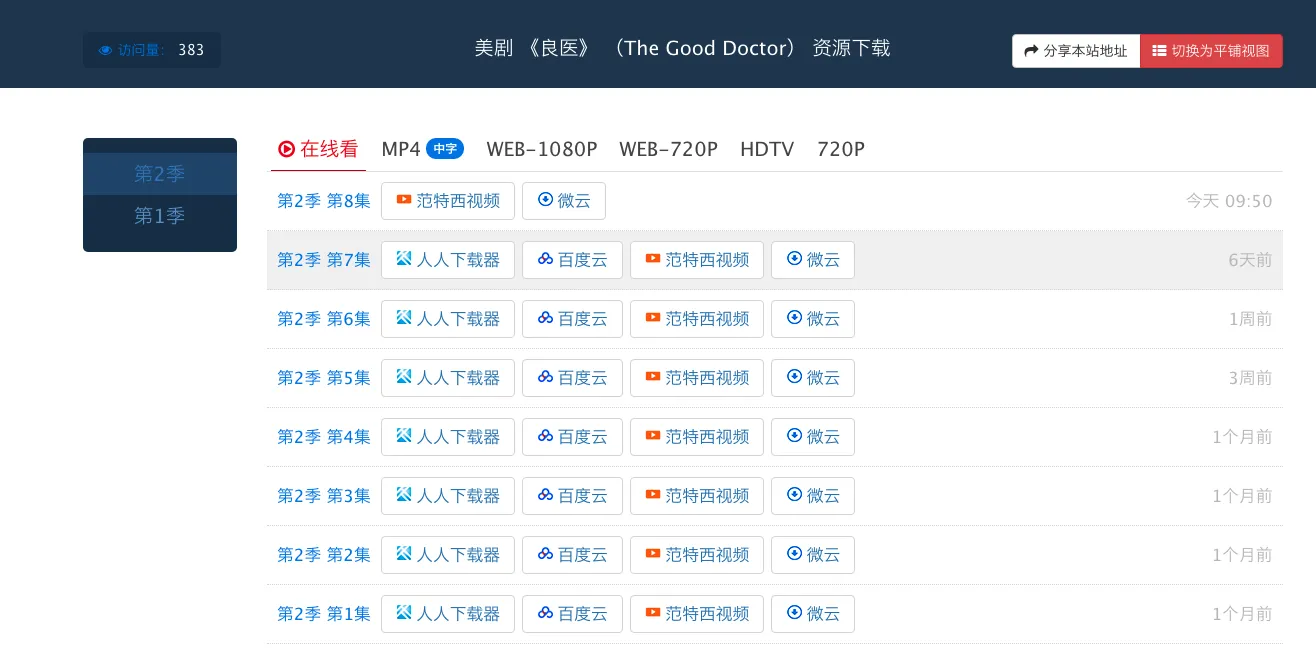 在下载地址包含各种地址,而我就只需要迅雷,电驴,磁力地址就够了,因此需要过滤掉其他的资源地址。查看源码可以发现
在下载地址包含各种地址,而我就只需要迅雷,电驴,磁力地址就够了,因此需要过滤掉其他的资源地址。查看源码可以发现div.col-infomation >div.tab-content >div.tab-pane的css选择器就可以把不同的季分出来,然后电影的话在查看电影的源码后可以了解其实电影相当于只有一季的电视剧,所以,可以把每一季单独看做一个独立的影视存储就好了。这里是获取详情页部分的代码
def parse(self, response):
item={}
base_name = response.css("span.name-chs::text").extract_first()
if u">正片<" not in response.text: ###这里去掉在线观看影视
item['movie_name'] = [base_name+i for i in response.css("ul.tab-side >li>a::text").extract()]
item['movie_link'] = []
for i in response.css("div.col-infomation >div.tab-content >div.tab-pane"):
item['movie_link'].append(self.get_tv_link(i,base_name))
yield item
else:
item['movie_name'] = [base_name]
item['movie_link'] = [self.get_movie_link(response,base_name)]
yield item
<h2><code></code></h2>
def get_tv_link(self, response,base_name):
movie_link = '<p class="download">下载地址:</p><div class="download">\n'
for i in response.css("ul.down-list >li.item"):
if u'人人下载器' not in i.extract():#去除人人下载器地址
ep_name = base_name + i.css("span.episode::text").extract_first()
links = i.css("a.btn::attr(href)").extract()
for link in links:
if link[:4]!="http": #去除百度网盘等其他网站直接链接地址
movie_link +='<p><a href="%s">%s</a></p>\n'%(link,ep_name)
movie_link +="\n</div>"##为了下一步的展示,直接使用html形式返回item
return movie_link
def get_movie_link(self, response,base_name):
response = response.css("div.col-infomation >div.tab-content >div.tab-pane")[0]
movie_link = '<p class="download">下载地址:</p><div class="download">\n'
for i in response.css("ul.down-list"):
if u'人人下载器' not in i.extract():
ep_name = i.css("span.filename::text").extract_first()
links = i.css("a.btn::attr(href)").extract()
for link in links:
if link[:4]!="http":
movie_link +='<p><a href="%s">%s</a></p>\n'%(link,ep_name)
movie_link +="\n</div>"
return movie_link
html形式保存爬取的影视资源
这里为了能够利于后面的解析,使用\n\n\t\n\n分割不同的季,\n\t\n分割季的名称以及它的链接地址。
class RenrenPipeline(object):
def __init__(self):
self.filet = open('movie.html', 'w',encoding="utf8")
def close_spider(self, spider):
self.filet.close()
def process_item(self, item, spider):
for i in range(len(item["movie_name"])):
self.filet.write(item["movie_name"][i]+"\n\t\n"+item["movie_link"][i]+"\n\n\t\n\n")
看一下抓取的效果吧
《刺心》
<p class="download">下载地址:</p><div class="download">
<p><a href="thunder://QUFlZDJrOi8vfGZpbGV8JUU1JTg4JUJBJUU1JUJGJTgzLjIwMTguV0VCLjEwODBwLiVFNCVCOCVBRCVFNSVBRCU5NyVFNyVBRSU4MCVFNCVCRCU5My4lRTUlQkMlQUYlRTUlQkMlQUYlRTUlQUQlOTclRTUlQjklOTUlRTclQkIlODQlMjYlRTglQkYlOUMlRTklODklQjQlRTUlQUQlOTclRTUlQjklOTUlRTclQkIlODQubXA0fDU4OTA1MTAyNTd8NzEwZmM4MDc0ZmE1MWI1ZmJiODcwNTM3OTUwMTU2NTZ8aD1nNm1xemp6ajVkMnprczZxNDdhc214NmNqeGo3YndlNHwvWlo=">刺心.2018.WEB.1080p.中字简体.完整版.弯弯字幕组&远鉴字幕组.mp4</a></p>
<p><a href="ed2k://|file|%E5%88%BA%E5%BF%83.2018.WEB.1080p.%E4%B8%AD%E5%AD%97%E7%AE%80%E4%BD%93.%E5%BC%AF%E5%BC%AF%E5%AD%97%E5%B9%95%E7%BB%84%26%E8%BF%9C%E9%89%B4%E5%AD%97%E5%B9%95%E7%BB%84.mp4|5890510257|710fc8074fa51b5fbb87053795015656|h=g6mqzjzj5d2zks6q47asmx6cjxj7bwe4|/">刺心.2018.WEB.1080p.中字简体.完整版.弯弯字幕组&远鉴字幕组.mp4</a></p>
<p><a href="magnet:?xt=urn:btih:5e78674237e944726e77cd15dc4b45f7aef4ae05&tr=udp://9.rarbg.to:2710/announce&tr=udp://9.rarbg.me:2710/announce&tr=http://tr.cili001.com:8070/announce&tr=http://tracker.trackerfix.com:80/announce&tr=udp://open.demonii.com:1337&tr=udp://tracker.opentrackr.org:1337/announce&tr=udp://p4p.arenabg.com:1337&tr=wss://tracker.openwebtorrent.com&tr=wss://tracker.btorrent.xyz&tr=wss://tracker.fastcast.nz">刺心.2018.WEB.1080p.中字简体.完整版.弯弯字幕组&远鉴字幕组.mp4</a></p>
<p><a href="thunder://QUFlZDJrOi8vfGZpbGV8JUU1JTg4JUJBJUU1JUJGJTgzLjEwODBwLiVFNiVCMyU5NSVFOCVBRiVBRCVFNCVCOCVBRCVFNSVBRCU5Ny4lRTQlQkElQkYlRTQlQjglODclRTUlOTAlOEMlRTQlQkElQkElRTUlQUQlOTclRTUlQjklOTUlRTclQkIlODQlMjYlRTYlQTklOTglRTklODclOEMlRTYlQTklOTglRTYlQjAlOTQlRTglQUYlOTElRTUlODglQjYlRTclQkIlODQubXA0fDE4Mzk2OTc3MDd8Y2U3OGRhMTE3MDMxYjI1NmNlYTlkZWQ4ZTc2NDdiNzR8aD15NmxxYTNrNHVtcXRkc2VyZWtjYWdrNHlpenptcHoyZ3wvWlo=">刺心.2018.WEB.1080p.中字简体.完整版.弯弯字幕组&远鉴字幕组.mp4</a></p>
<p><a href="ed2k://|file|%E5%88%BA%E5%BF%83.1080p.%E6%B3%95%E8%AF%AD%E4%B8%AD%E5%AD%97.%E4%BA%BF%E4%B8%87%E5%90%8C%E4%BA%BA%E5%AD%97%E5%B9%95%E7%BB%84%26%E6%A9%98%E9%87%8C%E6%A9%98%E6%B0%94%E8%AF%91%E5%88%B6%E7%BB%84.mp4|1839697707|ce78da117031b256cea9ded8e7647b74|h=y6lqa3k4umqtdserekcagk4yizzmpz2g|/">刺心.2018.WEB.1080p.中字简体.完整版.弯弯字幕组&远鉴字幕组.mp4</a></p>
<p><a href="ed2k://|file|%E5%88%BA%E5%BF%83.1080p.%E6%B3%95%E8%AF%AD%E4%B8%AD%E5%AD%97.%E4%BA%BF%E4%B8%87%E5%90%8C%E4%BA%BA%E5%AD%97%E5%B9%95%E7%BB%84%26%E6%A9%98%E9%87%8C%E6%A9%98%E6%B0%94%E8%AF%91%E5%88%B6%E7%BB%84.mp4|1839697707|ce78da117031b256cea9ded8e7647b74|h=y6lqa3k4umqtdserekcagk4yizzmpz2g|/">刺心.2018.WEB.1080p.中字简体.完整版.弯弯字幕组&远鉴字幕组.mp4</a></p>
浏览器打开保存的html后,是这样的。

看起来很丑,因为html也没有使用css渲染,想要下载的话直接点击就是了。
当然代码写的不是很好,有兴趣的自己改改吧,但是能用就行,有一句IT界名言来着,DONE IS BETTER THEN PERFECT ! 在获得具体地址后,获取下载地址详情页其实也可以使用scrapy-redis模块来进行分布式下载,但是好像没什么必要。一来下载站是限时下载的,超时后就会被删除资源。二来更新的内容不会太多,100个影视之内。当然如果有需要全站下载的那就需要了。下面是源码地址
github地址:https://github.com/tengbozhang/renren
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/43.html
- 版权声明:本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。