Python 查询最新到期删除域名
很多人找域名时,最费时间的不是注册动作本身,而是反复刷平台、筛条件、找出那些值得继续观察的过期域名。手工做这件事很慢,因此更适合先把“筛选”这一步脚本化。
这篇文章的重点不是自动帮你注册域名,而是自动整理一批符合条件的待观察域名列表,后续再由你自己决定是否预订或注册。
国内的域名商很多,这里以阿里为例,说明脚本化自动找寻心仪的域名的方法。
先说明两个现实限制
- 这里分析的是网页请求参数和查询结果,平台接口、参数名、token 规则后续都有可能变化。
- 脚本输出的是候选域名列表,不保证你最终一定能注册成功,因为平台状态会实时变化。
网络请求分析
首先分析阿里域名筛选的请求参数和内容,方便进行python自动化运行。 打开域名交易首页 由于最便宜的域名注册方式就是重新注册已经过期的域名,因此这里选择万网预订
用来建站,自然不用哪些垃圾域名后缀,这里只选择com。注册日期当然也早越好,这里最早为2006,到现在也是14年的老域名了,因此选择2006。状态选择未预定。通过谷歌浏览器的网络栏找到对应的带参数的搜索域名请求地址为 domainapi.aliyun.com,参数可以通过浏览器查看,如图
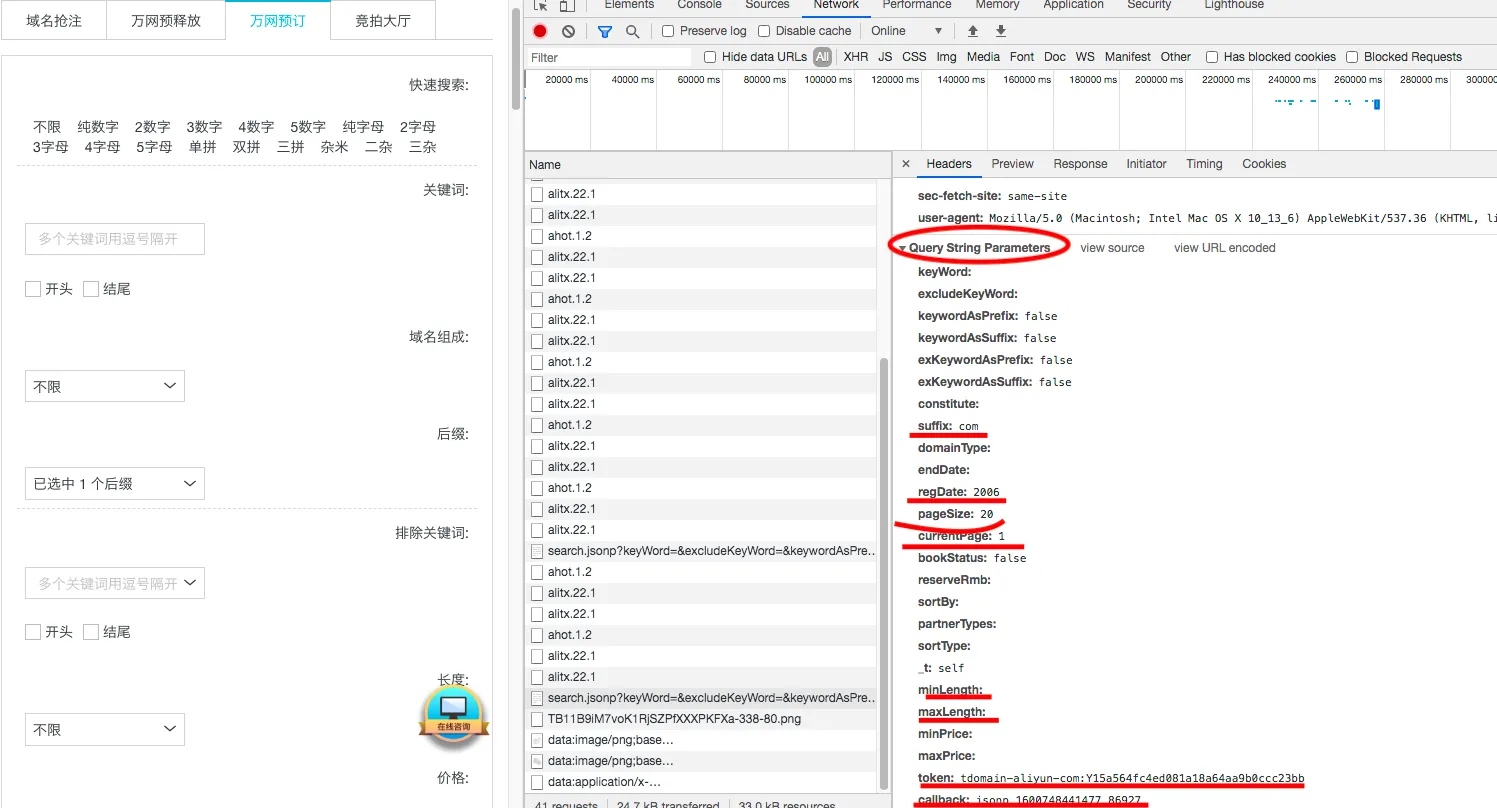
可以看到get请求中的参数详情
- suffix:对应域名后缀
- regDate: 对应注册时间
- pageSize: 对应每一页域名数量,可通过修改此参数一次性获取不超过1000个的域名
- currentpage: 对应当前所在页
- bookstatus: 表明是否被预定,false为未预定,true为已预定
- maxLength: 域名长度,当然越短越好,我设置为5
- token: 鉴权参数,后面分析
- callback: 返回格式,为方便我们可以改为json格式,python的json包就可以直接使用了
其实比较关键的就是token参数的获取了,通过搜索网络请求并没有找到该请求的来源,那么就没有办法获取鉴权的token了吗?当然不是
这里可以通过迂回的方式获得,获得参数必定通过浏览器请求,那么没有发现该请求自然时因为它可能通过jquery请求而没有记录,我们可以通过请求最原始的地址来获取,也就是阿里云域名预注册。为防止请求被刷新,首先需要打开谷歌浏览器的记录历史请求的选项,如图:

然后重新打开一个干净的标签页,打开审查选项,选上如上图所示的记录历史,访问阿里云域名预注册,
找到当前的token为Y15a564fc4ed081a18a64aa9b0ccc23bb
接下来搜索html和json请求找到token出现位置

自动查询注册域名
上面网络请求已经很清晰了,接下来只需要根据请求一步步编写自动话脚本了。
下面这份脚本更适合做“批量筛选”,也就是先拿回候选列表,再按你自己的偏好做二次过滤。
直接上代码:
# 该脚本运行后将会在当前目录生成包含可注册域名列表的ali_domain.txt文件
# 并不包含自动在运营商注册的内容
# 请知悉
## 先导入必要的包
import requests
import pandas as pd
import json
import time
TIMEOUT = 10
headers = {"Referer":"https://wanwang.aliyun.com/domain/reserve",
"user-agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) Apple: WebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36",
}
def get_token():
tokenurl = "https://promotion.aliyun.com/risk/getToken.htm"
text = requests.get(tokenurl,headers=headers).text
return json.loads(text)["data"]
def get_domains(token,regd="2006"):
### 这里根据参数直接修改就行,我设置的是一页100条记录,也就是100个域名,查看第一页就好了
### 后缀 com,域名长度最大为5,返回设置为json
url = "https://domainapi.aliyun.com/preDelete/search.jsonp?keyWord=&excludeKeyWord=&keywordAsPrefix=false&keywordAsSuffix=false&exKeywordAsPrefix=fa\
lse&exKeywordAsSuffix=false&constitute=&suffix=com&domainType=&endDate=®Date={}&pageSize=100¤tPage=1&bookStatus=false&reserveRmb=&sortBy=1&pa\
tnerTypes=&sortType=1&_t=self&minLength=&maxLength=5&minPrice=&maxPrice=&token=tdomain-aliyun-com%3A{}&callback=json".format(regd,token)
text = requests.get(url,headers=headers,timeout = TIMEOUT).text
#根据json结构获取内容
domains = json.loads(text.split("(")[1].split(")")[0])
return domains
## 这里手动添加 token(示例值通常会过期)
token = "Y15a564fc4ed081a18a64aa9b0ccc23bb"
## 这里通过阿里的 API 自动获取 token
token = get_token()
print(token)
## 搜索到的域名保存文件名
filename = "ali_domain.tsv"
## 每次运行是更新文件内容
with open("ali_domain.tsv",'w') as fw:
fw.close()
# 从2006年到2010 年逐年搜索并写入到csv文件
for i in range(2006,2010):
domains = get_domains(token,regd=str(i))
if domains["code"]=="200":
domains = domains["data"]["pageResult"]["data"]
domains = pd.DataFrame.from_dict(domains)
domains = domains[~domains.short_name.str.contains("-")]
print(domains)
domains.to_csv(filename,index=None,mode="a",sep="\t")
time.sleep(20)
新脚本
import sys
import requests
import pandas as pd
import json
import time
import os
os.environ['HTTP_PROXY'] = 'http://127.0.0.1:1081'
TIMEOUT = 10
headers = {"Referer":"https://wanwang.aliyun.com/domain/reserve",
"user-agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) Apple: WebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36",
}
def get_token():
tokenurl = "https://promotion.aliyun.com/risk/getToken.htm"
text = requests.get(tokenurl,headers=headers).text
return json.loads(text)["data"]
def get_df(token,regd="2006"):
url = f"https://domainapi.aliyun.com/preDelete/search.jsonp?keyWord=&excludeKeyWord=&keywordAsPrefix=false&keywordAsSuffix=false&exKeywordAsPrefix=false&exKeywordAsSuffix=false&constitute=&suffix=com&domainType=&endDate=®Date=&pageSize=500¤tPage=1&bookStatus=0&reserveRmb=&sortBy=1&patnerTypes=&sortType=1&_t=self&minLength=&maxLength=8&minPrice=&maxPrice=&token=tdomain-aliyun-com%3A{token}&callback=json"
#print(url)
text = requests.get(url,headers=headers,timeout = TIMEOUT).text
res = json.loads(text.split("(")[1].split(")")[0])
return res
token = get_token()
filename = "/home/teng/ali.txt"
def has_pairs(s):
if s[0]==s[1] or s[1]==s[2] or s[2]==s[3]:
return True
return False
df_list = []
# Loop through the years and process the data
for i in range(2006, 2010):
df = get_df(token, regd=str(i))
if df["code"] == "200":
df = df["data"]["pageResult"]["data"]
df = pd.DataFrame.from_dict(df)
# Filter out rows based on the conditions
filters = ['-', 'z', '2', 'i', 'l', '1', 'o', '0','q','9','g']
for f in filters:
df = df[~df.short_name.str.contains(f)]
# Apply the has_pairs function
df['pairs'] = df['short_name'].apply(has_pairs)
df = df[df.pairs == True]
# Append the filtered dataframe to the list
df_list.append(df)
domains = pd.concat(df_list, ignore_index=True)
ori = pd.read_csv(filename, sep=',')
domains = domains.drop_duplicates()
print(domains)
domains = pd.concat([ori, domains]).reset_index(drop=True)
domains = domains.drop_duplicates()
domains.to_csv(filename, index=None, mode="w")
运行后查看文件部分内容
head -n 40 ali_domain.tsv
结果如下,当前域名在2020年09月22日生成,其他结果自行运行脚本吧,如果大家有需求的话我再在网站上另外做一个网页专门显示最新可注册4-5位的com域名。
beian book_status domain_len domain_name end_date price reg_date short_name pairs
0 0 0 4 n344.com 2025-06-06 83.0 2021-12-14 n344 True
1 0 0 4 6ycc.com 2025-06-06 83.0 2023-03-20 6ycc True
2 0 0 4 6fpp.com 2025-06-06 83.0 2024-04-15 6fpp True
3 0 0 4 t33k.com 2025-06-06 83.0 2023-03-28 t33k True
4 0 0 4 y55n.com 2025-06-06 83.0 2018-10-20 y55n True
5 0 0 4 k88u.com 2025-06-06 83.0 2024-03-28 k88u True
6 0 0 4 kkt8.com 2025-06-06 83.0 2021-03-18 kkt8 True
7 0 0 4 aad4.com 2025-06-06 83.0 2024-03-18 aad4 True
8 0 0 4 xx4x.com 2025-06-06 83.0 2021-03-19 xx4x True
9 0 0 4 5khh.com 2025-06-06 83.0 2012-03-18 5khh True
10 0 0 4 yaa4.com 2025-06-06 83.0 2024-03-18 yaa4 True
11 0 0 4 77u5.com 2025-06-06 83.0 2024-03-17 77u5 True
12 0 0 4 ppk5.com 2025-06-06 83.0 2015-03-27 ppk5 True
13 0 0 4 b4mm.com 2025-06-06 83.0 2024-03-20 b4mm True
14 0 0 4 s66r.com 2025-06-07 83.0 2023-03-21 s66r True
15 0 0 4 u66b.com 2025-06-07 83.0 2023-03-21 u66b True
16 0 0 4 y77n.com 2025-06-07 83.0 2019-08-15 y77n True
17 0 0 4 ww7c.com 2025-06-07 83.0 2024-03-29 ww7c True
总结
这篇文章的核心思路其实很简单:先分析请求参数,再把常用筛选条件脚本化,最后把候选域名保存成文件,供自己继续人工判断。这样做能明显减少反复点筛选器的时间。
如果脚本突然失效,优先检查 3 个地方:token 是否过期、请求参数名是否变了、以及返回结构里的 JSON 路径是否被平台调整。
通过该脚本每天都可以发现好几个可以注册的2006年左右注册的长度为4位数的老域名,老域名还真的是挺多的,接下来只需要到喜欢的域名商中去预定就好了,当然我们只注册别人忘记续费的域名,所以只需要基础的注册价就可以注册到了。通过这种方式,已经注册了好几个域名,比如好看头像,趣事追踪,然后惊喜的发现域名注册日期变成了2020年,也就是说别人过期的域名重新注册的话,日期是重新计算的,对域名注册商来说也就跟新域名差不多,但是对seo的影响就不知道了。
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/731.html
- 版权声明:本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。