利用Python递归下载文件夹下所有文件
2018-12-08
技术
最近想备份网站文件,但 PHP 直接下载大文件有大小限制,我又不想额外开 FTP 去慢慢拖文件,于是就想到:如果目标目录本身能以索引页方式访问,那完全可以直接用 Python 把整个目录树递归拉下来。
这篇文章演示的就是这种最简单的思路:识别目录、自动建本地文件夹、递归进入子目录、遇到文件就直接下载。
1.安装requests库
pip install requests
2.下载文件夹下所有文件及文件夹
这里需要处理的地方主要是文件夹,这里我们判断出该链接是文件夹时,自动创建文件夹,并递归继续进行操作,否则判断该链接是文件,直接使用requests get方法下载,话不多说,看代码
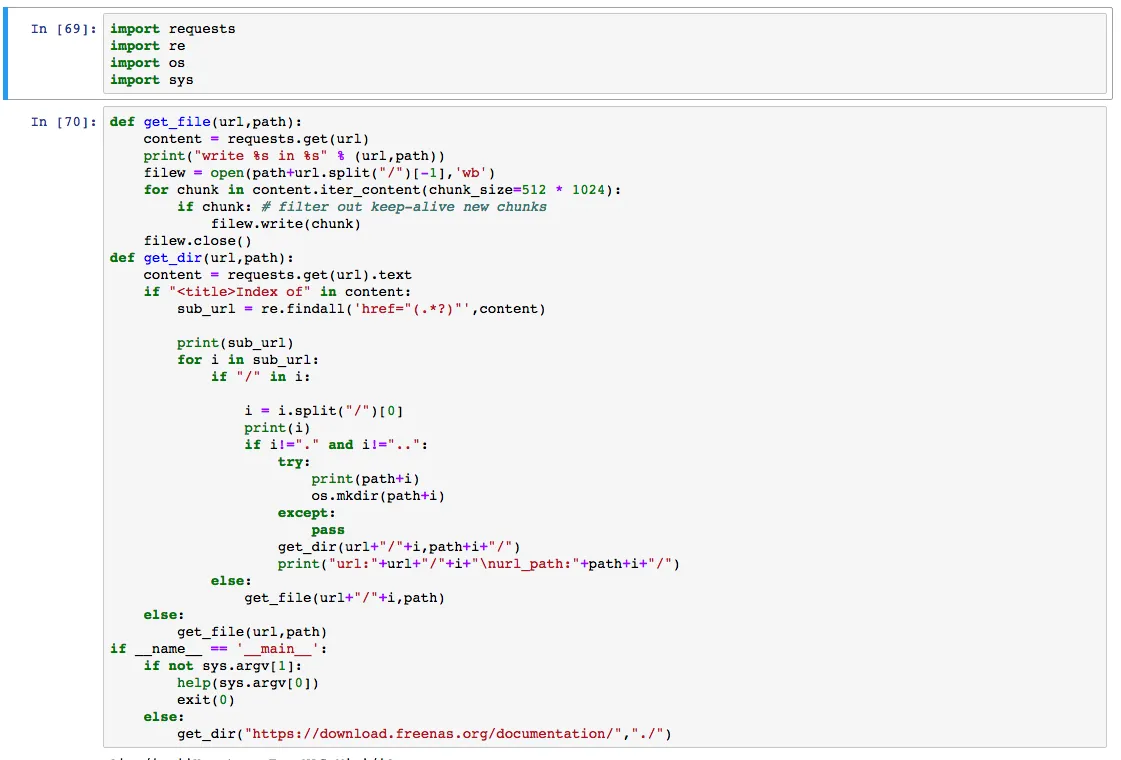
import requests
import re
import os
import sys
def help(script):
text = 'python3 %s https://www.bobobk.com ./' % script
print(text)
def get_file(url,path):##文件下载函数
content = requests.get(url, stream=True)
print("write %s in %s" % (url,path))
filew = open(path+url.split("/")[-1],'wb')
for chunk in content.iter_content(chunk_size=512 * 1024):
if chunk: # filter out keep-alive new chunks
filew.write(chunk)
filew.close()
def get_dir(url,path): #文件夹处理逻辑
content = requests.get(url).text
if "<title>Index of" in content:
sub_url = re.findall('href="(.*?)"',content)
print(sub_url)
for i in sub_url:
if "/" in i:
i = i.split("/")[0]
print(i)
if i!="." and i!="..":
if not os.path.exists(path+i):
os.mkdir(path+i)
get_dir(url+"/"+i,path+i+"/")
print("url:"+url+"/"+i+"\nurl_path:"+path+i+"/")
else:
get_file(url+"/"+i,path)
else:
get_file(url,path)
if __name__ == '__main__':
if len(sys.argv)<=1:
help(sys.argv[0])
exit(0)
else:
get_dir(sys.argv[1],"./")
使用时注意
- 这种方法更适合目标站点本身开启了目录索引的情况。
- 如果站点关闭了目录列表、需要登录、或者依赖动态接口,这份脚本就不够用了。
- 做备份时建议先在测试目录运行一次,避免把无关的大文件全部拉下来。
至此,就可以在本地目录把原网站的路径结构和文件基本还原出来了。对于简单静态资源目录,这种方法非常直接。
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/85.html
- 版权声明:本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。