机器学习中混淆矩阵详解:TP、TN、FP、FN 与 Precision、Recall 计算
做分类模型时,模型给出一个“是”或“否”的结果并不够,我们还需要知道它到底错在什么地方。比如一个模型总是把正类漏掉,和一个模型总是把负类误报成正类,业务后果完全不同。
这就是混淆矩阵的作用。它不是只给你一个总分,而是把分类结果拆成几个最基础的格子,让你能进一步计算 precision、recall、accuracy 和 F1 这些常见指标。
本文会覆盖下面几个部分:
- 什么是混淆矩阵
- 二分类问题的混淆矩阵计算
开始前先记住一个判断顺序
理解 TP、TN、FP、FN 时,最容易混淆的地方是“先看预测结果,还是先看真实结果”。一个实用记忆方法是:
- 先看模型预测的是正类还是负类
- 再看这个预测到底对不对
于是就得到:
- 预测为正且预测正确,是真阳性 TP
- 预测为正但预测错误,是假阳性 FP
- 预测为负且预测正确,是真阴性 TN
- 预测为负但预测错误,是假阴性 FN
什么是混淆矩阵
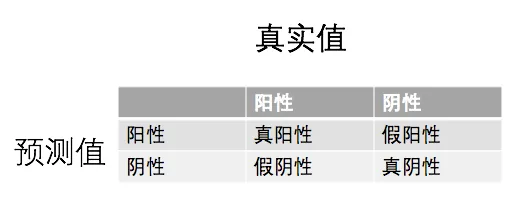
在二分类问题里,混淆矩阵通常由 4 个最基础的结果组成:
- 真阳性(True Positive, TP):真实为正,预测也为正
- 假阴性(False Negative, FN):真实为正,但预测为负
- 假阳性(False Positive, FP):真实为负,但预测为正
- 真阴性(True Negative, TN):真实为负,预测也为负
如下图所示:
下面用一个怀孕检测的例子来理解:

真阳性:
检测结果显示“怀孕”,真实结果也确实是怀孕。
真阴性:
检测结果显示“没有怀孕”,真实结果也确实没有怀孕。
假阳性(一型错误):
检测结果显示“怀孕”,但真实结果并没有怀孕。
比如一个没有怀孕的人却被检测为怀孕。
假阴性(二型错误):
检测结果显示“没有怀孕”,但真实结果其实已经怀孕。
总的来说,记住“先看预测正负,再看对错”即可。
二分类问题的混淆矩阵计算
知道了混淆矩阵的 4 个格子,接下来就可以计算常见评估指标了,最常见的是 recall、precision、accuracy 和 F1。
recall计算
recall = TP/(TP+FN)
它表示:在所有真实为正的样本中,有多少被模型成功找出来了。
如果你的任务更怕“漏掉正类”,通常就会更看重 recall,比如疾病筛查、风控预警等场景。
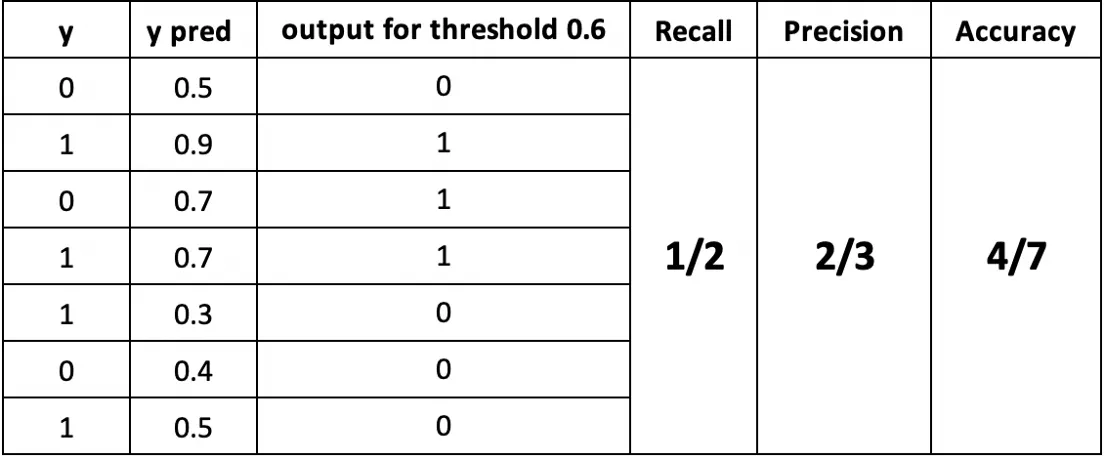
例子中,第 2、4、5、7 个样本真实为正,模型只预测出第 2、4 个,因此 recall 是 2/4 = 1/2。
precision计算
precision = TP/(TP+FP)
它表示:在所有被模型预测为正的样本中,真正为正的比例是多少。
如果你的任务更怕“误报正类”,通常会更看重 precision,比如垃圾邮件过滤、人工审核前置筛选等场景。
例子里,一共预测了 3 个样本(第 2、3、4 个)为正,真实为正的是第 2、4 个,因此 precision 是 2/3。
accuracy 计算
accuracy = (TP+TN)/(TP+FP+TN+FN)
它表示:所有样本里,被正确分类的比例。
例子中一共 7 个样本,其中第 1、2、4、6 个分类正确,因此 accuracy 是 4/7。
不过 accuracy 有一个明显问题:当类别极不平衡时,它可能看起来很高,但模型实际没什么用。
实际情况中,如果两个算法在 recall 和 precision 上表现不一致,往往还需要一个综合指标,这里就会用到 F-measure,也就是常说的 F1。
f-measure 计算
f-measure 一般指 F1 值:
f_measure = 2*recall*precision/(recall + precision)
F1 同时考虑了 recall 和 precision,适合在两者都重要时比较模型优劣。
混淆矩阵在实际中怎么用
看混淆矩阵时,不要只盯着一个指标。更实用的做法是先问自己:
- 业务里最怕的是漏报,还是误报
- 类别是不是严重不平衡
- 是不是需要在 precision 和 recall 之间做阈值取舍
例如:
- 医疗筛查通常更关注 recall,因为漏掉真正阳性的代价更高
- 广告点击或推荐过滤有时更关注 precision,因为误报会带来更多无效结果
- 样本极度不平衡时,单看 accuracy 往往不够,最好至少再看 precision、recall 和 F1
总结
本文介绍了机器学习分类任务中最基础也最重要的评估工具之一:混淆矩阵,并进一步说明了 TP、TN、FP、FN 的含义,以及如何由它们计算 recall、precision、accuracy 和 F1。
真正使用时,重点不是死记公式,而是先判断业务更怕哪一种错误,再结合混淆矩阵选择合适的指标。只要这个判断顺序理清了,很多分类模型评估问题都会更容易看懂。
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/932.html
- 版权声明:本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。