预处理方法怎么选:MinMaxScaler、StandardScaler、RobustScaler 与 Normalizer 区别
机器学习里,预处理通常不是“顺手做一下”的小步骤,而是会直接影响模型表现的重要环节。尤其当不同特征的量纲差异很大,或者数据里存在明显离群值时,不同的缩放方式可能会让模型效果差很多。
sklearn 里围绕这个问题最常见的几个名字是:MinMaxScaler、StandardScaler、RobustScaler 和 Normalizer。它们看起来都像“归一化”,但实际处理目标并不一样。
这篇文章先把概念分清,再用一组模拟数据看看不同方法处理前后的变化,最后给出更实用的选择建议。
定义
先把几个容易混淆的词分开:
scale:广义上指“改变数值尺度”standardize:通常指减去均值、再除以标准差,让数据变成均值接近 0、标准差接近 1normalize:在很多文章里会和前两者混着说,但在sklearn里,Normalizer更具体,指把每一行样本缩放到单位范数
也就是说,StandardScaler、MinMaxScaler、RobustScaler 通常都是按列处理特征,而 Normalizer 更多是按行处理样本。
开始前先记住一个判断顺序
如果你只想先快速选一个方法,可以先按下面这个顺序判断:
- 特征量纲差很多,但离群值不严重,优先看
StandardScaler - 希望把值压到固定区间,比如
[0, 1],优先看MinMaxScaler - 数据里离群值明显,优先看
RobustScaler - 如果你更关心样本向量方向,而不是单个特征绝对大小,比如文本向量或余弦相似度场景,再看
Normalizer
原因
为什么这些预处理会影响模型表现?
因为不少算法对特征尺度非常敏感。如果一个特征的数值范围在几千,另一个特征只在 0 到 1 之间,模型很可能会过度依赖前者。
常见受影响比较明显的算法包括:
- 线性回归
- KNN
- NN
- SVM
- PCA
- LDA
尤其是基于距离、梯度或特征方差的算法,通常更依赖合适的预处理。
生成测试数据
这里用 np.random 生成一组模拟数据,分别包含 beta 分布、指数分布、正态分布,以及均值和方差更大的正态分布,用来观察不同缩放方法的效果。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置种子,保证数据可重现
np.random.seed(1024)
data_beta = np.random.beta(1, 2, 1000)
data_exp = np.random.exponential(scale=2, size=1000)
data_nor = np.random.normal(loc=1, scale=2, size=1000)
data_bignor = np.random.normal(loc=2, scale=5, size=1000)
# 生成dataframe
df = pd.DataFrame({
"beta": data_beta,
"exp": data_exp,
"bignor": data_bignor,
"nor": data_nor,
})
df.head()
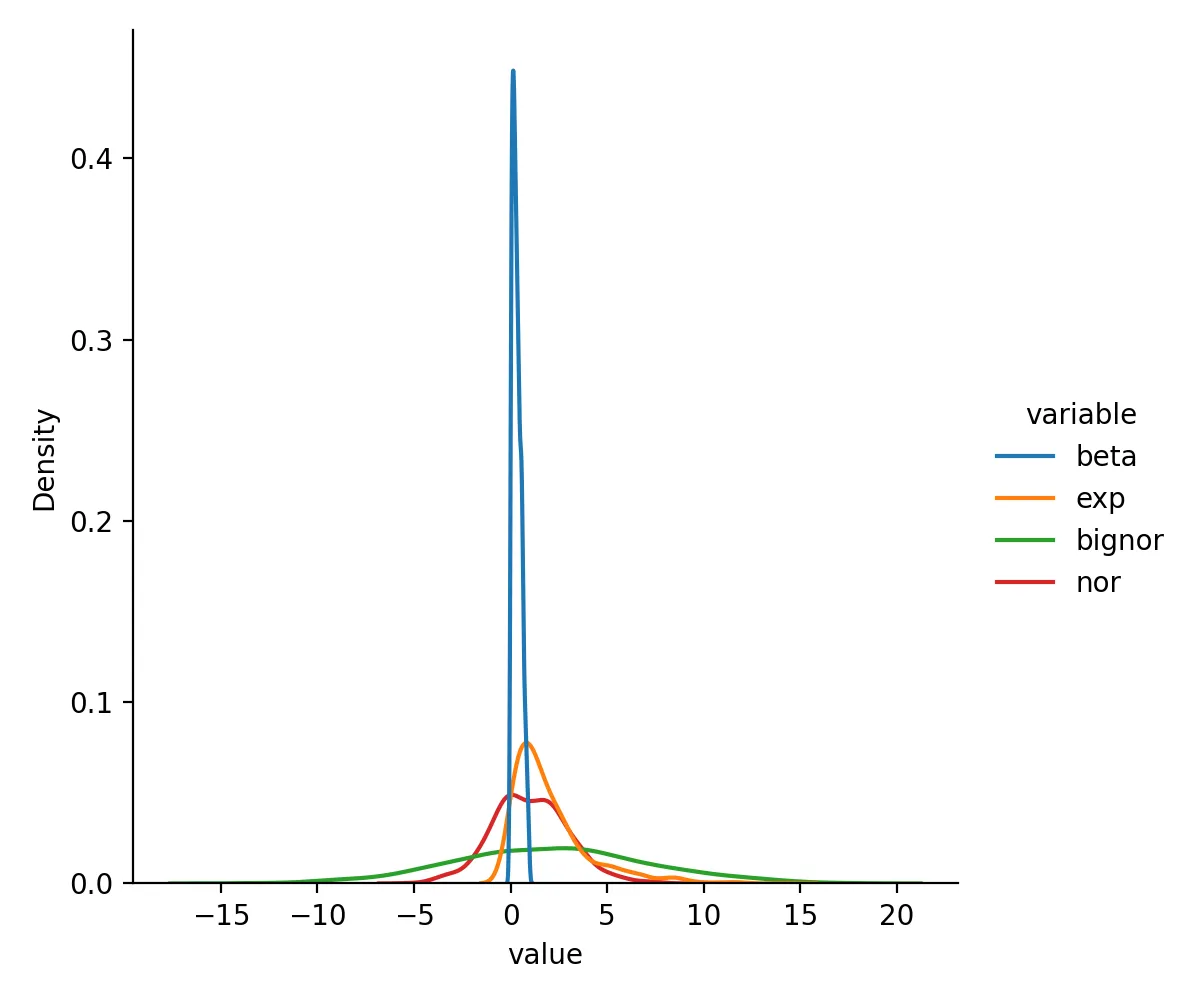
先看原始分布:
sns.displot(df.melt(), x="value", hue="variable", kind="kde")
plt.savefig("origin.png", dpi=200)
比较不同处理后数据变化情况
下面分别使用 MinMaxScaler、RobustScaler 和 StandardScaler 进行处理并比较。这里先不把 Normalizer 混在一起,因为它处理的是“每一行样本”,逻辑和前面三个不一样。
MinMaxScaler
MinMaxScaler 会把每一列特征线性压缩到固定区间,默认是 [0, 1]。
from sklearn.preprocessing import MinMaxScaler
df_minmax = pd.DataFrame(MinMaxScaler().fit(df).transform(df), columns=df.columns)
sns.displot(df_minmax.melt(), x="value", hue="variable", kind="kde")
plt.savefig("minmaxscaler.png", dpi=200)
plt.close()
MinMaxScaler 转换后数据变成这样:
beta exp bignor nor
0 0.402556 0.077887 0.623988 0.662302
1 0.344735 0.058066 0.671804 0.635879
2 0.050261 0.587947 0.573984 0.249901
3 0.113638 0.568196 0.767447 0.483282
4 0.394540 0.190253 0.661321 0.662763
分布为:
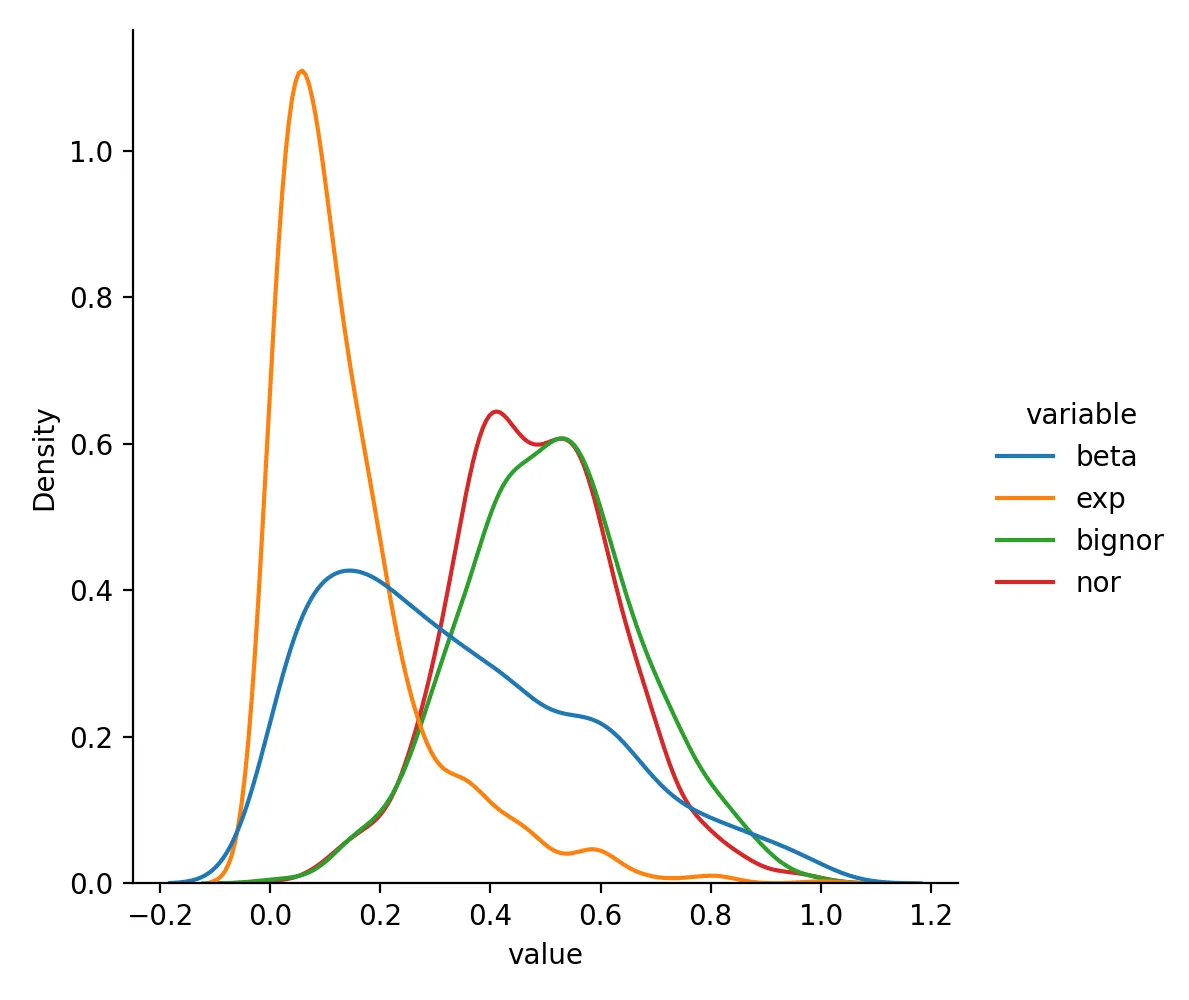
它的优点是范围固定、直观,但如果数据里有极端离群值,其他大多数样本会被一起压缩得很厉害。
RobustScaler
RobustScaler 使用中位数和四分位距来缩放,因此对离群值更稳。
from sklearn.preprocessing import RobustScaler
df_rsca = pd.DataFrame(RobustScaler().fit(df).transform(df), columns=df.columns)
sns.displot(df_rsca.melt(), x="value", hue="variable", kind="kde")
plt.savefig("robustscaler.png", dpi=200)
plt.close()
RobustScaler 转换后数据变成这样:
beta exp bignor nor
0 0.284395 -0.141315 0.551292 0.923234
1 0.126973 -0.278467 0.779068 0.790394
2 -0.674763 3.388036 0.313090 -1.150118
3 -0.502211 3.251365 1.234674 0.023211
4 0.262573 0.636202 0.729129 0.925553
分布为:
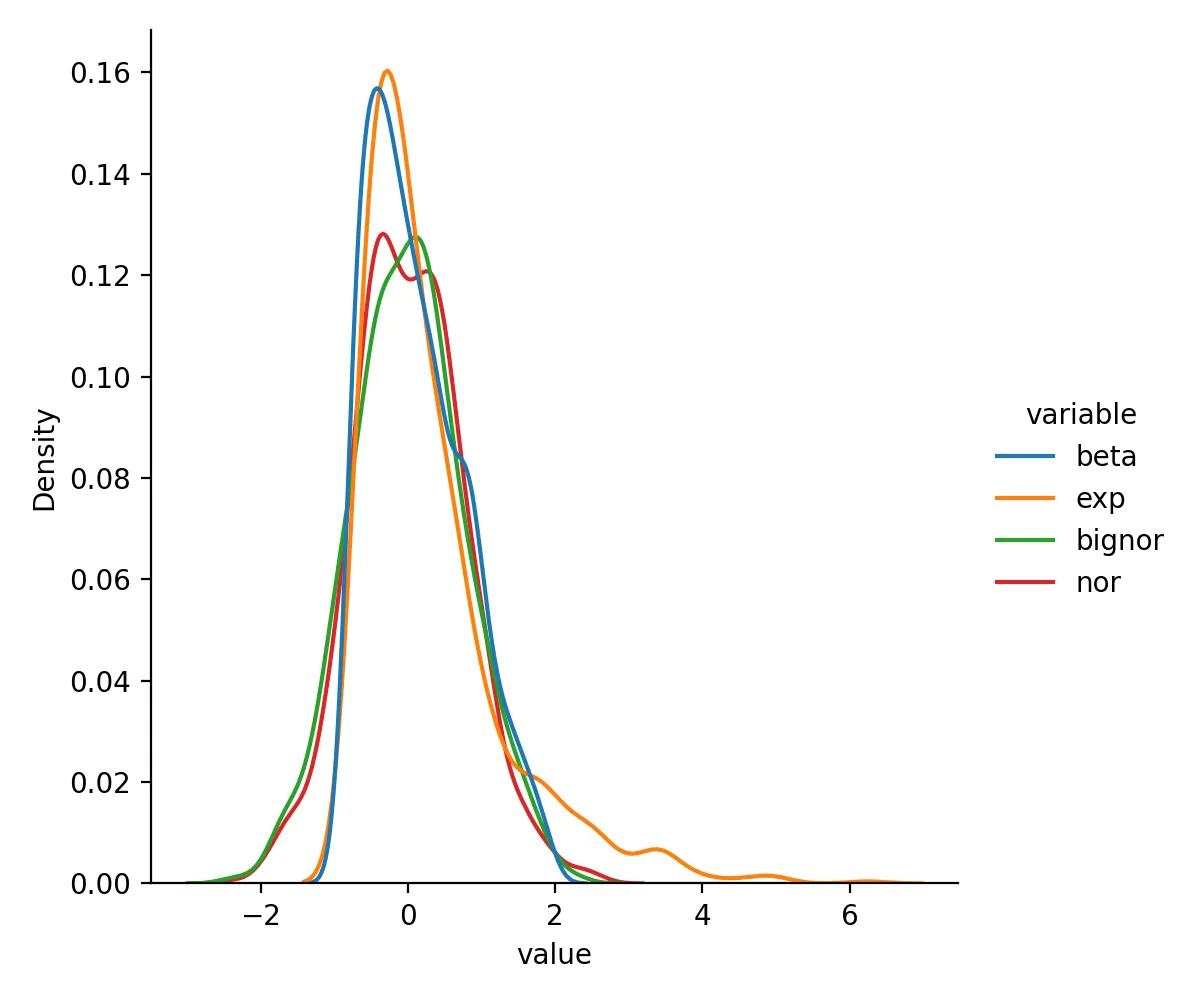
如果你的数据明显偏态,或者已经知道存在一批极端值,RobustScaler 往往会比 StandardScaler 更稳一些。
StandardScaler
StandardScaler 是最常见的标准化方式:均值变成接近 0,标准差变成接近 1。
from sklearn.preprocessing import StandardScaler
df_std = pd.DataFrame(StandardScaler().fit(df).transform(df), columns=df.columns)
sns.displot(df_std.melt(), x="value", hue="variable", kind="kde")
plt.savefig("standardscaler.png", dpi=200)
plt.close()
StandardScaler 转换后数据变成这样:
beta exp bignor nor
0 0.252859 -0.460413 0.711804 1.207845
1 0.012554 -0.600899 1.008364 1.030065
2 -1.211305 3.154733 0.401670 -1.566938
3 -0.947902 3.014740 1.601554 0.003337
4 0.219547 0.336005 0.943345 1.210949
分布为:
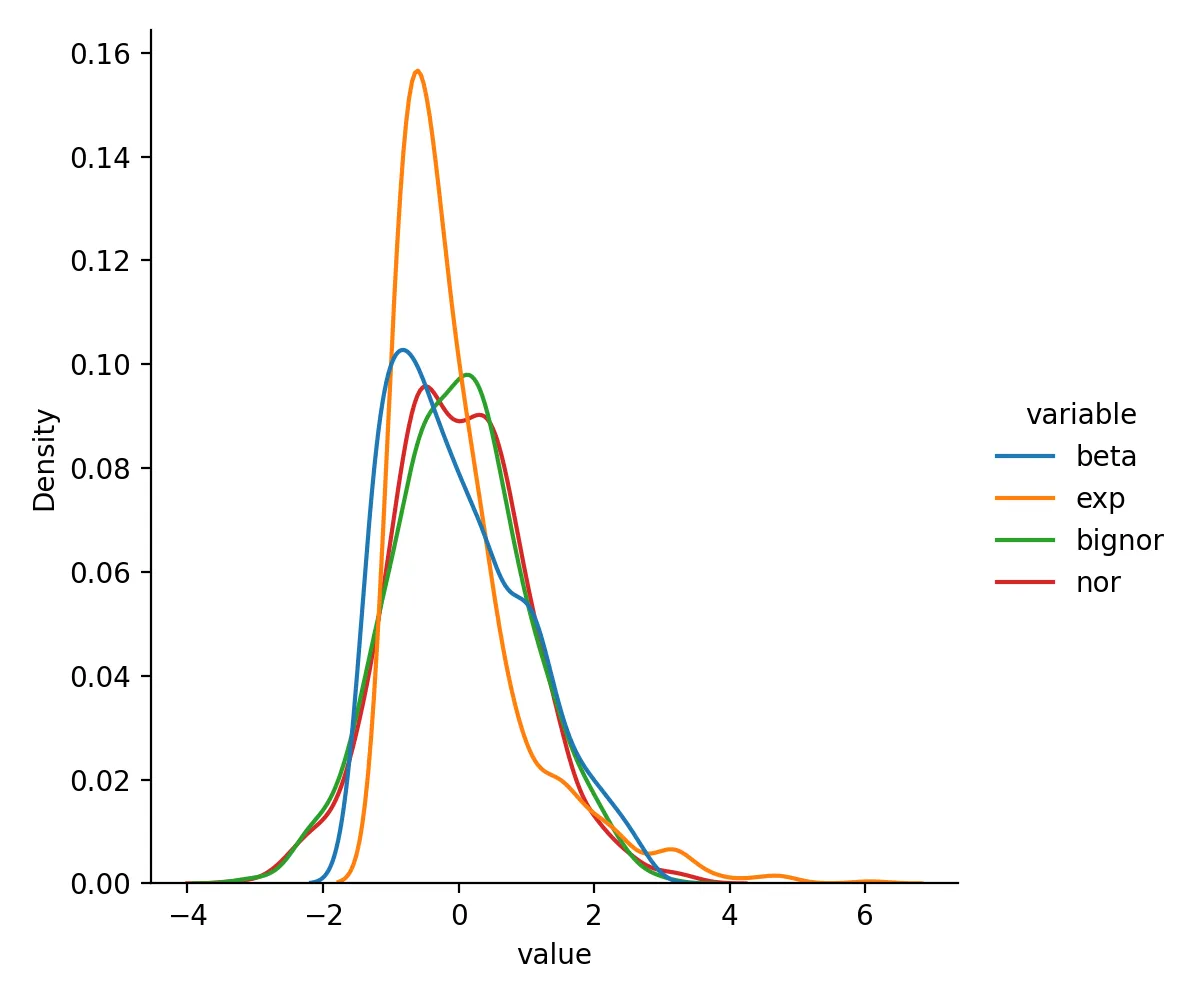
如果你没有特别强的理由选别的,StandardScaler 往往是很多连续型数值特征的默认起点。
Normalizer 和前面三个有什么不同
Normalizer 很容易和前面三个混淆,但它的目标不一样。前面三个通常都是按列处理特征,而 Normalizer 是按行处理每个样本,把每个样本缩放到单位范数。
一个简单例子:
from sklearn.preprocessing import Normalizer
sample = pd.DataFrame({
"x1": [3, 1],
"x2": [4, 2]
})
Normalizer().fit_transform(sample)
# array([[0.6 , 0.8 ],
# [0.4472136 , 0.89442719]])
这类处理常见于:
- 文本向量
- 稀疏特征
- 更关注向量方向而不是绝对大小的相似度计算
所以它和 StandardScaler、MinMaxScaler 并不是简单替代关系。
实际中该怎么选
如果只想要一个简单实用的选择建议,可以记住下面这张表:
| 方法 | 主要作用 | 更适合的情况 |
|---|---|---|
MinMaxScaler |
压到固定区间 | 神经网络输入、需要固定边界时 |
StandardScaler |
变成均值 0、方差 1 | 大多数连续数值特征的默认选择 |
RobustScaler |
对离群值更稳 | 偏态分布或异常值明显的数据 |
Normalizer |
让每个样本单位范数化 | 文本向量、余弦相似度等场景 |
真正落地时,不要只看名字,而要先问:
- 我是在按特征缩放,还是按样本缩放?
- 数据里有没有明显离群值?
- 下游模型到底是更看重距离、梯度,还是向量方向?
总结
本文比较了 MinMaxScaler、StandardScaler、RobustScaler 和 Normalizer 这几种常见预处理方法,并解释了它们在处理目标上的差异。
如果你处理的是普通连续数值特征,StandardScaler 往往是最常见的起点;如果离群值明显,就优先看 RobustScaler;如果必须压缩到固定区间,就考虑 MinMaxScaler;如果你关心的是每个样本向量的方向而不是绝对大小,再考虑 Normalizer。
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/981.html
- 版权声明:本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。