python实现酷狗音乐mp3下载
在python实现千千音乐mp3下载 后小伙伴使用发现很多音乐在千千音乐都搜不到,所以今天春江暮客就拓展了一下酷狗音乐的下载,有源码。
同样的配方,首先在酷狗官网上直接搜索歌曲,然后打开谷歌浏览器的网络监视器,再次搜索同样的关键字就可以发现接口信息(注:此处最好再次搜索的时候查看网络,可以剔除很多多余的信息)。
1.分析搜索接口信息
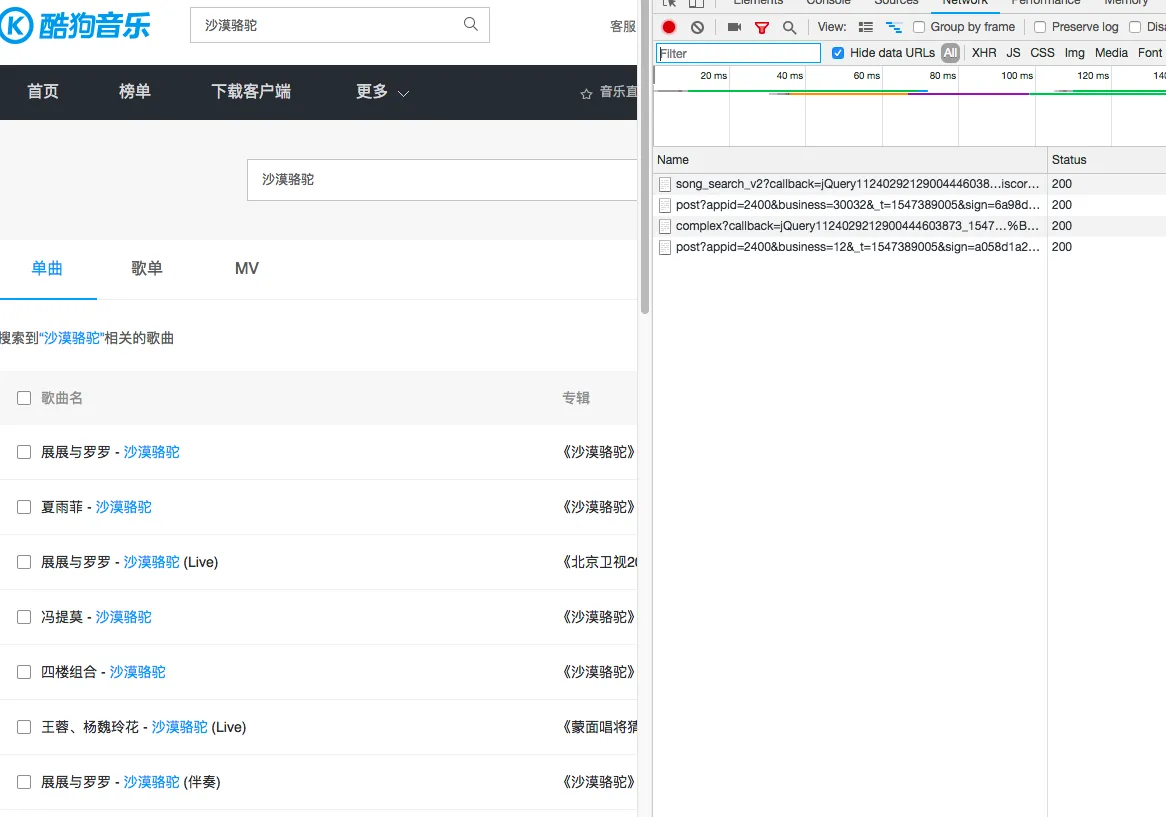 只有4条网络请求,可以很方便的知道是第一条请求是真正的返回了歌曲信息,因此构造此条请求即可。
只有4条网络请求,可以很方便的知道是第一条请求是真正的返回了歌曲信息,因此构造此条请求即可。
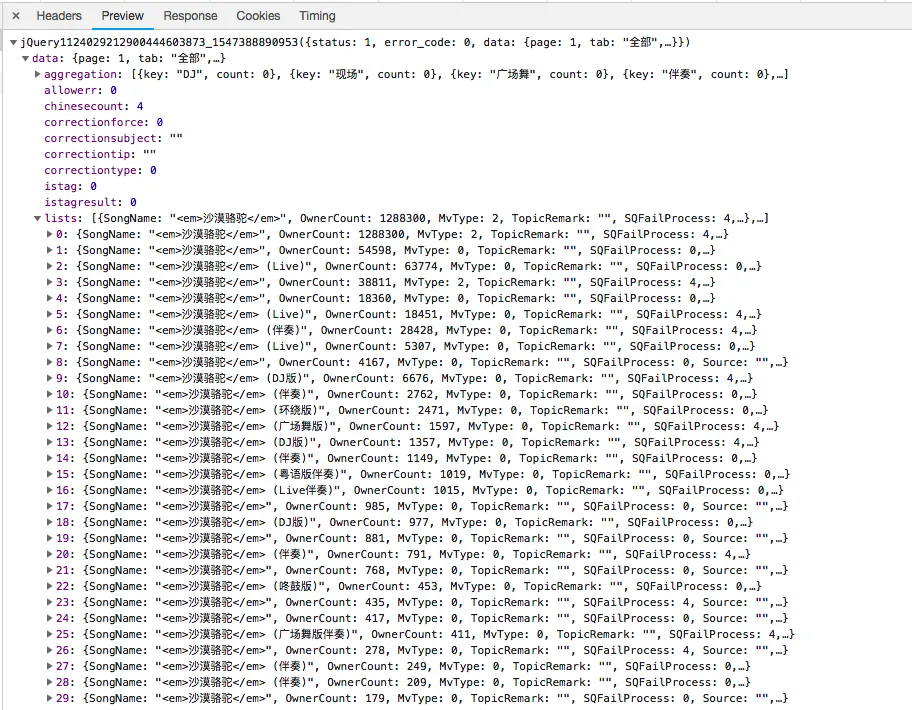
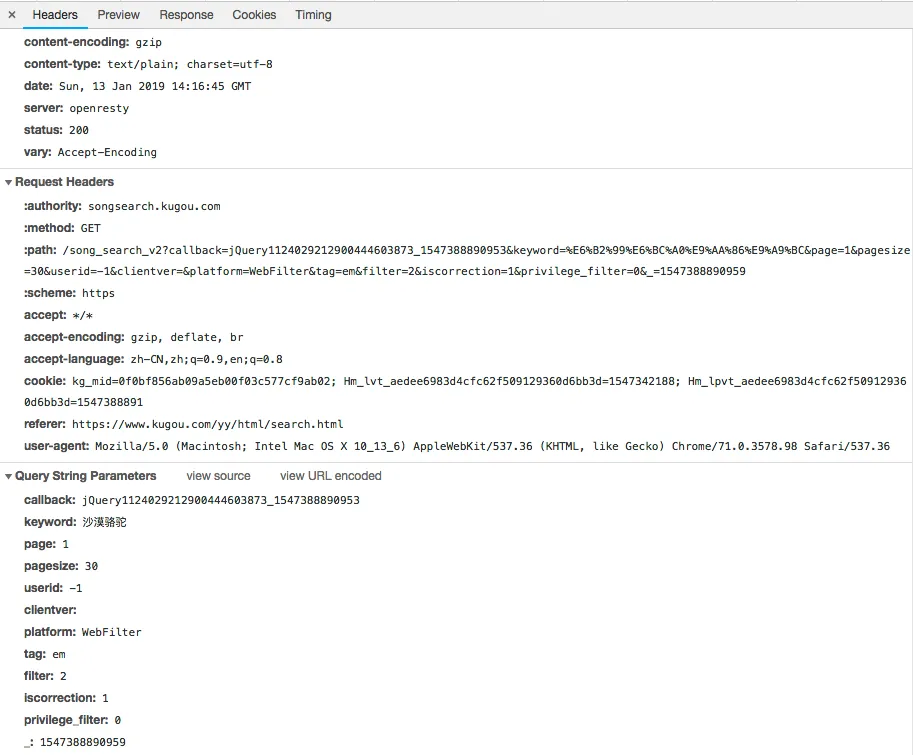
请求详细信息,在看了千千音乐的文章后,相信大家也熟悉了,callback是前面加上13位的timestamp时间戳,_为13位的timestamp时间戳。
2.分析播放接口信息
到这里已经知道了搜索的详细请求以及结果,接下来看音乐下载地址,点击第一首歌曲播放
查看url为https://www.kugou.com/song/#hash=0D0CD85787B2988DC372A315EFD632FC&album_id=2713184,由此直接知道要想获得音乐下载地址,只需要一个hash,一个album_id,回到上一步搜索结果,看看response里面的两个信息。
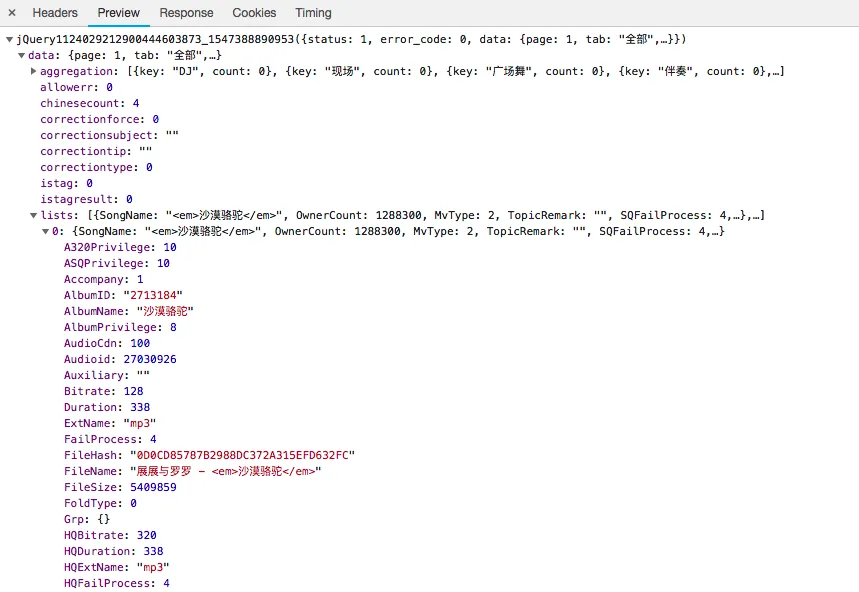
只需要使用json解析结果然后获取信息,json_page_source[“data”][“list”][0][“AlbumID”]和json_page_source[“data”][“list”][0][“FileHash”]即可获取下载所需信息。
直接查看网络,刷新,查看网络连接,从茫茫多的请求中找到真正的获取mp3地址的请求。
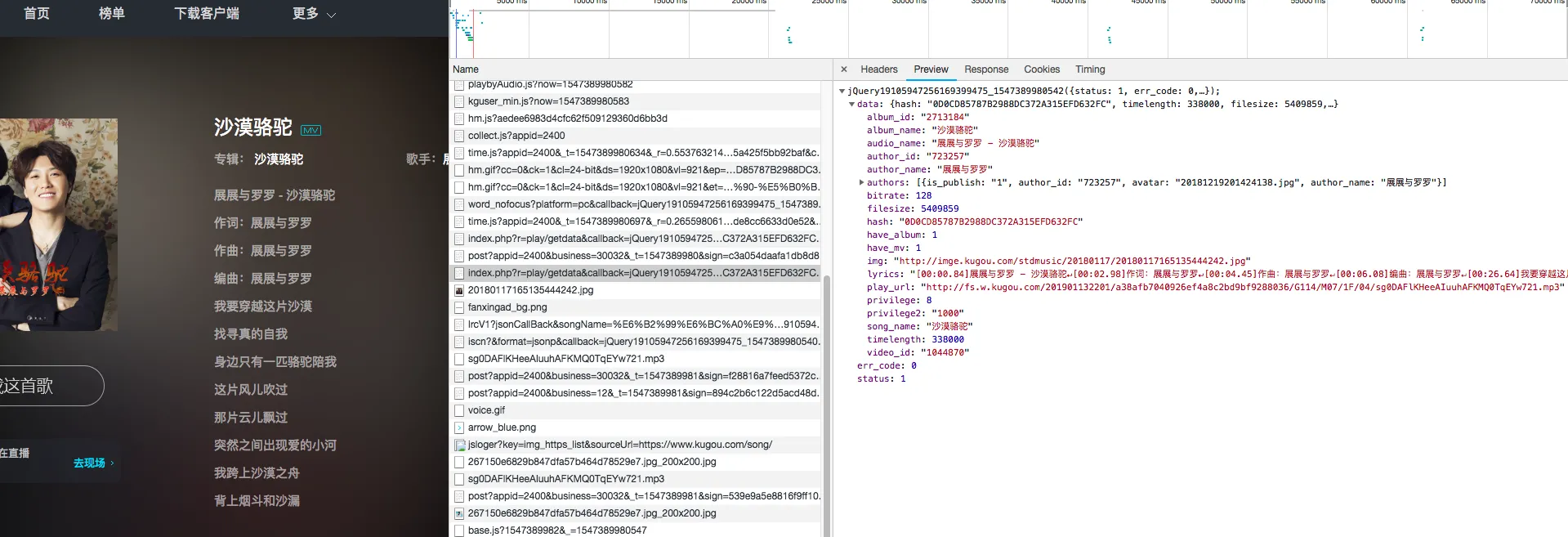
同样是json,同样的配方。play_url为mp3地址,lyc歌词信息直接以文本格式返回,lyrics。json_page_source[“data”][“play_url”]得到mp3地址,json_page_source[“data”][“lyrics”]获取lrc歌词。
3.python实现搜索下载
接口分析清楚了,就可以直接上python了,这里酷狗对爬虫限制比较严格,不知道为什么requests获取不到信息,因此借助万能的selenium实现调用浏览器获取源码,然后mp3再用requests下载。上代码
#!env python
# -*- coding: utf-8 -*-
import requests
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import re,json,time,sys,os
CHROME_PATH = os.getcwd()+"/chromedrive"
#print(CHROME_PATH)
def helpmessage():
msg = r'''
/\ /\ /\ /\
/\//\\/\ /\//\\/\ /\//\\/\ /\//\\/\
/\//\\\///\\/\//\\\///\\/\//\\\///\\/\//\\\///\\/\
//\\\//\/\\///\\\//\/\\///\\\//\/\\///\\\//\/\\///\\
\\//\/ \/\\//
\/ 本程序由 春江暮客 \/
/\ 发布在www.bobobk.com 上 /\
//\\ 程序打开后会打开网站 //\\
\\// 大家不要急着关闭 \\//
\/ 作者:春江暮客 \/
/\ 酷狗音乐下载 /\
//\\ 用法看程序运行时界面 //\\
\\// 如有任何疑问请在 \\//
\/ 博客页面留言或者发邮件到 \/
/\ 2180614215@qq.com /\
//\\ 下载的音乐仅供学习交流 //\\
\\// 严禁用于商业用途 \\//
\/ 请于24小时内删除 \/
/\ /\
//\\/\ /\//\\
\\///\\/\//\\\///\\/\//\\\///\\/\//\\\///\\/\//\\\//
\/\\///\\\//\/\\///\\\//\/\\///\\\//\/\\///\\\//\/
\/\\//\/ \/\\//\/ \/\\//\/ \/\\//\/
\/ \/ \/ \/
'''
print(msg)
#####图案由boxes生成,不懂请看https://www.bobobk.com/185.html
def get_kugou_mp3_address_and_download(song_hash,albumid):
apiurl= "https://wwwapi.kugou.com/yy/index.php"
chrome_url = apiurl+"?"+"r=play/getdata&hash=%s&album_id=%s" % (song_hash,albumid)
browser = webdriver.Chrome(CHROME_PATH)
browser.get(chrome_url)
text = json.loads(browser.page_source.split("")[1].split("")[0])
browser.close()
song_address = text["data"]["play_url"]
songname = text["data"]["author_name"]+"_"+text["data"]["album_name"]+"_"+text["data"]["song_name"]
mp3w = open(songname+".mp3",'wb')
mp3r = requests.get(song_address)
for chunk1 in mp3r.iter_content(chunk_size=512 * 1024):
if chunk1:
mp3w.write(chunk1)
mp3w.close()
lrc = open(songname + ".lrc",'w')
lrc.write(text["data"]["lyrics"])
lrc.close()
def search_music(keyword):
if keyword in ["exit",u"退出"]:
print(u"你选择了退出当前程序")
sys.exit(0)
callback = "jQuery112404564878798811507_"+str(round(time.time()*1000))
hua = str(round(time.time()*1000))
basic_url = 'https://songsearch.kugou.com/song_search_v2?'
kugou_s_url = basic_url + "callback=%s&keyword=%s&page=1&pagesize=40&userid=-1&clientver=2.7.8&platform=WebFilter&tag=em&filter=2&iscorrection=7&privilege_filter=0&_=%s" % (callback,keyword,hua)
browser = webdriver.Chrome(CHROME_PATH)
browser.get(kugou_s_url)
songlist = json.loads(browser.page_source.split(callback)[1].split("...")[0][1:-2].strip())["data"]["lists"]##...由于网页展示问题被替换
browser.close()
return songlist
def main():
while True:
song = input(u"请输入想要下载的音乐或歌手或专辑...名称: ").strip()
if song!="":
break
songlist = search_music(song)
page = 1
print("\n搜索结果如下")
for i in range(len(songlist)):
print("%d:%s_%s_%s" % (i+1,songlist[i]["SingerName"].replace("<","").replace(";",'').replace(">","").replace("em",'').replace("/",'').strip(),songlist[i]["AlbumName"],songlist[i]["SongName"].replace("<","").replace(";",'').replace(">","").replace("em",'').replace("/",'')))
print("\n")
while True:
songid = input(u'请选择想要下载的歌曲前面的数字\n多首歌曲以空格分开,如"1 2"回车\n输入非数字退出选择,进入搜索状态\n全部下载请输入100000:').strip()
if songid == '':
continue
try:
songid = [int(i) for i in songid.strip().split()]
# print(songid)
if songid[0] != 100000:
for song in songid:
# print(songlist[song-1]["FileHash"])
# print(songlist[song-1]["AlbumID"])
songname = songlist[song-1]["SingerName"].replace("<","").replace(";",'').replace(">","").replace("em",'').replace("/",'').strip()+"_"+songlist[song-1]["AlbumName"]+"_"+songlist[song-1]["SongName"].replace("<","").replace(";",'').replace(">","").replace("em",'').replace("/",'').strip()
try:
get_kugou_mp3_address_and_download(songlist[song-1]["FileHash"],songlist[song-1]["AlbumID"])
print(u"\n-------恭喜,当前歌曲--%s--下载完成---------\n" % songname)
except:
print("网络错误")
print(u"退出请输入'exit'或者'退出'")
else:
print("正在开始下载搜索到的所有歌曲,请耐心等待\n\n")
for songid in songlist:
print("-------正在下载歌曲--------%s----------" % songid[1])
time.sleep(2)
try:
get_mp3_address_and_download(songid[0])
print("-------恭喜,歌曲--------%s---下载完成-------\n" % songid[1])
except:
print("下载%s时错误发生" % songid[1])
except:
print("数字错误,重新搜索歌曲\n")
break
main()
if __name__=='__main__':
print("\n\n\n")
# search_music(u"可不可以")
# get_kugou_mp3_address_and_download("96E064A41AB84EBE4C03C6AAE3CB9334","9618875")
helpmessage()
os.system("start https://www.bobobk.com/234.html")
print("\n\n\n")
while True:
# main()
try:
main()
except:
print(u"2秒后关闭程序")
time.sleep(2)
sys.exit(0)
总结
本文是在python实现千千音乐mp3下载 后,发现很多资源没有,因此增加了这个酷狗音乐的下载程序,其中在使用requests获取网页的过程中遇到了障碍,不得不使用了selenium调用浏览器的方式获取。但是结果总是好的,最好还是完美的实现了酷狗音乐的下载。
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/234.html
- 版权声明:本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。