使用 Bootstrapping 计算置信区间:Python 重采样示例详解
置信区间(confidence interval, CI)用于描述“根据当前样本估计出来的统计量,大致会落在什么范围内”。在数据分析和科研里,95% 置信区间是最常见的表达方式。
这篇文章重点不放在公式推导,而是通过一个更实用的例子说明:如何用 Python 对一组样本做 bootstrapping 重采样,再用 bootstrap 后的统计量分布估计 95% 置信区间。
概念
简单理解,置信区间不是说“总体参数有 95% 概率在这个区间里”,而是说如果你反复独立采样、反复构造区间,其中大约 95% 的区间会覆盖真实总体参数。
为何使用置信区间
实际工作里,我们几乎总是先拿到样本,而不是完整总体。单个均值、单个比例或单条回归系数都不够表达不确定性,这时候置信区间就很重要:它能把“估计值”和“估计值的波动范围”一起表达出来。
置信区间的计算
如果数据近似正态分布,而且你使用的是经典参数法,那么常见置信水平对应的 z-score 如下:
置信区间 zscore
0.90 1.645
0.95 1.96
0.99 2.58
经典计算公式为:
也就是用样本均值加减误差项,得到区间上下界。
但在很多真实场景里,数据未必严格满足参数法假设,这时候 bootstrap 就是一种很常用的替代方案。
Bootstrapping 是怎么做的
bootstrap 的核心思路很简单:
- 从原始样本中“有放回”地抽样
- 每次抽出一个和原样本规模相同或指定规模的新样本
- 对每个新样本计算你关心的统计量,比如均值、中位数或回归系数
- 重复很多次后,统计量本身会形成一个经验分布
- 再从这个经验分布里取百分位数,得到近似置信区间
应用
下面用一个简单示例演示整个过程。这里我们关心的是:一组随机样本的均值,它的 95% bootstrap 置信区间大概是多少。
首先是数据的生成
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
np.random.seed(1024)
data_nor = np.random.normal(loc=1,scale=2,size=1000)
这里生成了一个均值约为 1、标准差约为 2 的模拟样本。
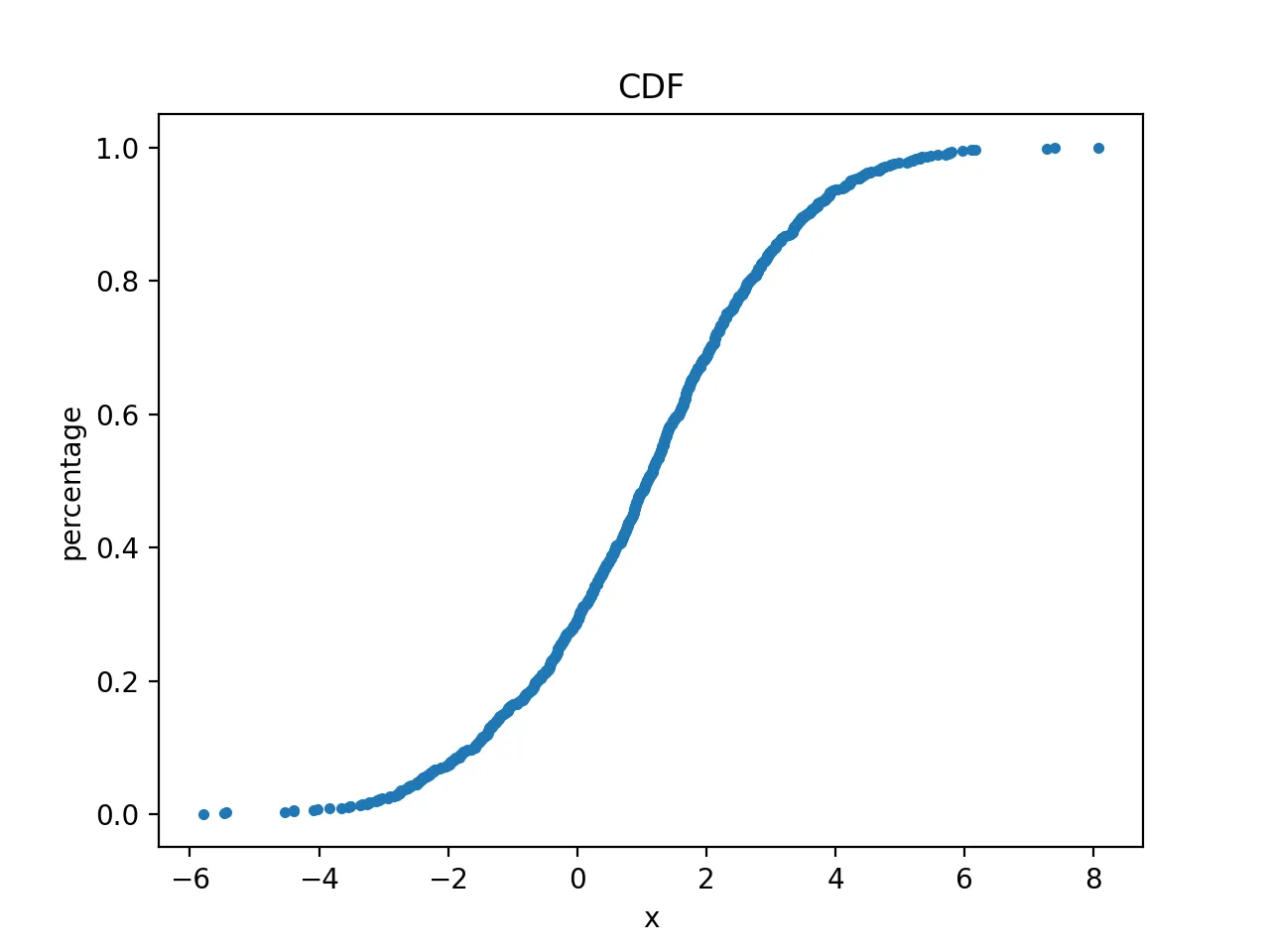
查看其累积曲线
先画一下经验累积分布函数(CDF):
x = np.sort(data_nor)
n = len(x)
y = np.arange(1,n+1)/n
plt.plot(x,y,marker='.',linestyle="none")
plt.xlabel("x")
plt.ylabel("percentage")
plt.title("CDF")
plt.savefig("cdf.png",dpi=200)
plt.close()
绘制得到的图形为:
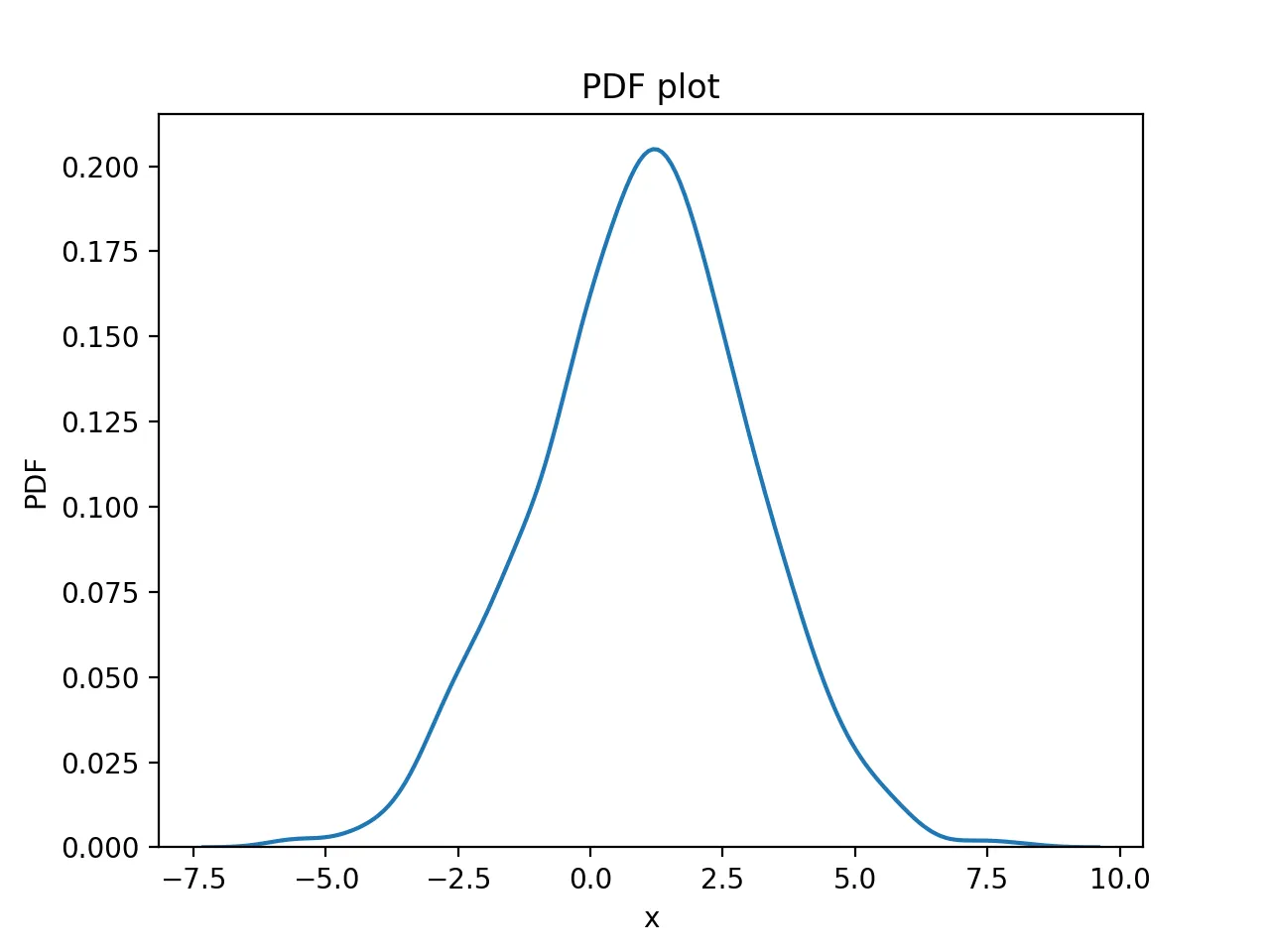
查看其密度曲线
再看一眼平滑后的密度曲线:
sns.kdeplot(data_nor, fill=False)
plt.xlabel("x")
plt.ylabel("PDF")
plt.title("PDF plot")
plt.savefig("pdf.png",dpi=200)
plt.close()
其图形为:
通过bootstrapping随机生成背景数据并计算置信区间
通过对 data_nor 有放回抽样,重复很多次,我们可以得到“样本均值”的 bootstrap 分布。这里要特别注意:
- 如果你想估计“均值的置信区间”,后面做 percentile 的对象应该是
bs_mean - 不是最后一次抽样得到的
bs_sample
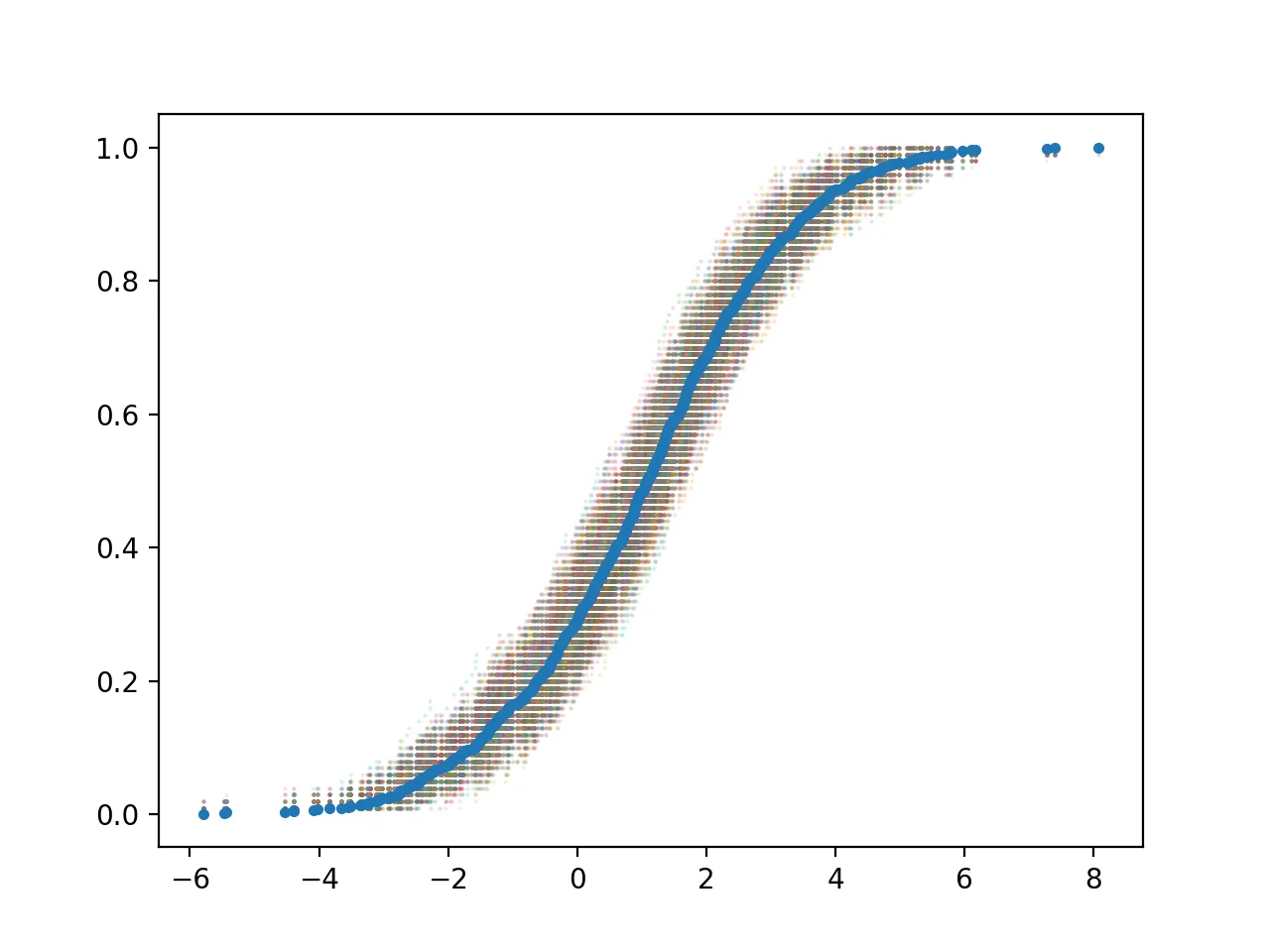
# 首先绘制原始数据作为中间曲线`
plt.plot(x,y,marker='.',linestyle="none")
bs_mean = []
for i in range(10000):
bs_sample = np.random.choice(data_nor, size=100, replace=True)
x_bs = np.sort(bs_sample)
bs_mean.append(np.mean(bs_sample))
n_bs = len(x_bs)
y_bs = np.arange(1, n_bs+1) / n_bs
plt.scatter(x_bs, y_bs, s=1, marker='.', alpha=0.02)
plt.savefig("bs.png",dpi=200)
plt.close()
绘制得到的图形为:
接着对 bs_mean 作图,并直接通过 np.percentile 取 2.5% 和 97.5% 分位数:
ci_low, ci_high = np.percentile(bs_mean, [2.5, 97.5])
plt.hist(bs_mean, bins=50, density=True)
plt.axvline(x=ci_low, ymin=0, ymax=1, label='2.5%', c='y')
plt.axvline(x=ci_high, ymin=0, ymax=1, label='97.5%', c='r')
plt.xlabel("x")
plt.ylabel("PDF")
plt.title("BS PDF")
plt.legend()
plt.savefig("percent.png",dpi=200)
plt.close()
图形为:
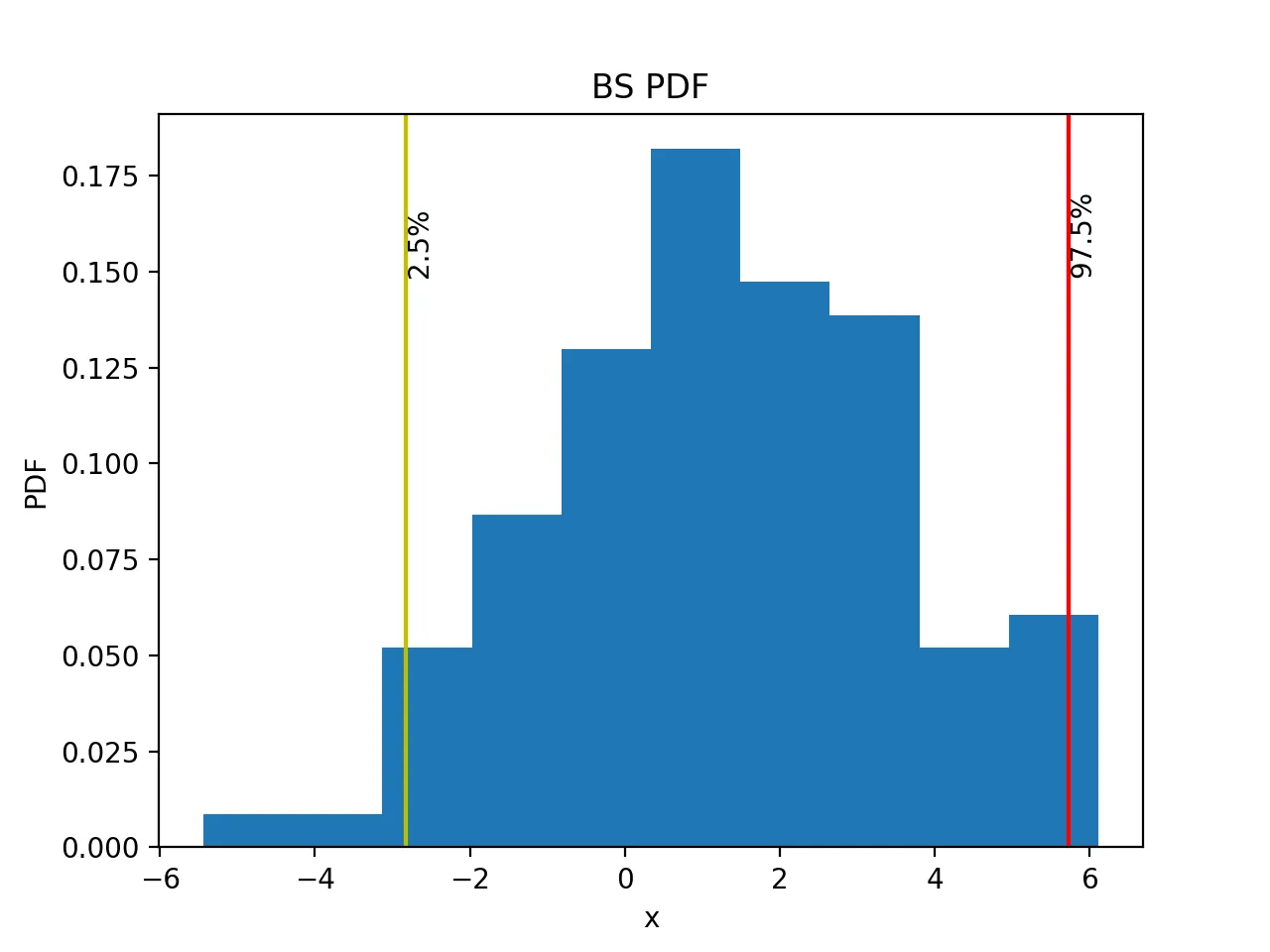
如果按这套思路计算,最终得到的 95% 置信区间应该解释为“样本均值的 bootstrap 置信区间”,而不是原始单次抽样值本身的区间。
你也可以直接打印结果:
print(ci_low, ci_high)
使用时的几个注意点
- bootstrap 重采样默认应当是“有放回抽样”,所以通常要显式写出
replace=True - 你要估计什么统计量,就应该对那个统计量的 bootstrap 结果取百分位数
sns.distplot已经是旧接口,新的代码更建议使用sns.kdeplot或sns.histplot- bootstrap 是近似方法,样本量太小或数据分布太极端时,结果仍然要谨慎解释
总结
本文介绍了置信区间的基本概念,并通过 Python 示例演示了如何使用 bootstrapping 对样本均值做重复重采样,再通过 percentile 方法估计 95% 置信区间。
这类方法的关键不在于“多抽几次样”本身,而在于先明确你要估计的统计量是什么,然后对这个统计量的 bootstrap 分布取区间。只要这个逻辑不混淆,bootstrap 在科研和数据分析里会非常实用。
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/838.html
- 版权声明:本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。