Confusion Matrix in Machine Learning: TP, TN, FP, FN, Precision, and Recall
When working on a classification model, one overall score is usually not enough. A model that misses many real positives is very different from a model that raises too many false alarms, even if their total accuracy looks similar.
That is why the confusion matrix matters. Instead of giving only one final score, it breaks prediction results into a small set of basic outcomes that can then be used to calculate precision, recall, accuracy, and F1.
This article covers these parts:
- What is a confusion matrix
- Calculation of confusion matrix in binary classification problems
A quick way to remember the four terms
The easiest way to avoid confusion is to use this order:
- First check whether the model predicted positive or negative
- Then check whether that prediction was correct
That gives you:
- Predicted positive and correct: True Positive (TP)
- Predicted positive and wrong: False Positive (FP)
- Predicted negative and correct: True Negative (TN)
- Predicted negative and wrong: False Negative (FN)
What is a Confusion Matrix
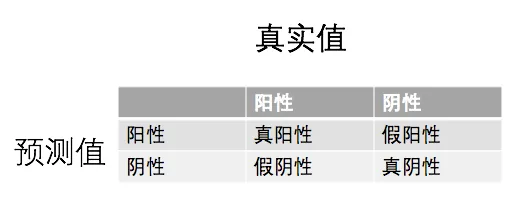
In binary classification, the confusion matrix is built from four basic outcomes:
- True Positive (TP): actually positive and predicted positive
- False Negative (FN): actually positive but predicted negative
- False Positive (FP): actually negative but predicted positive
- True Negative (TN): actually negative and predicted negative
As shown below:
Here is a more concrete example using a pregnancy test scenario:

True Positive:
The test result says “pregnant”, and the real result is also pregnant.
True Negative:
The test result says “not pregnant”, and the real result is also not pregnant.
False Positive (Type I error):
The test result says “pregnant”, but the actual result is not pregnant.
False Negative (Type II error):
The test result says “not pregnant”, but the actual result is actually pregnant.
In summary, first look at whether the prediction is positive or negative, then look at whether it is correct.
- If predicted positive and prediction is correct, it is True Positive.
- If predicted positive but prediction is wrong, it is False Positive.
- If predicted negative and prediction is correct, it is True Negative.
- If predicted negative but prediction is wrong, it is False Negative.
Calculation of Confusion Matrix in Binary Classification Problems
Once the four cells of the confusion matrix are clear, you can compute common metrics such as recall, precision, accuracy, and F1.
Recall Calculation
recall = TP / (TP + FN)
This measures how many of the truly positive samples were successfully found by the model.
If your task cares more about avoiding missed positives, recall becomes especially important.
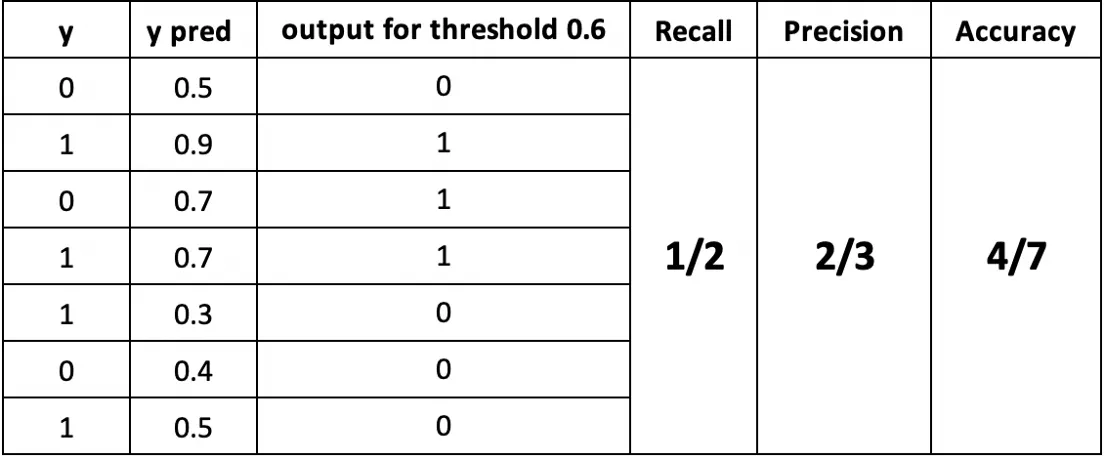
In the example, samples 2, 4, 5, and 7 are truly positive. The model predicts only 2 and 4 as positive, so recall is 2/4 = 1/2.
Precision Calculation
precision = TP / (TP + FP)
This measures how many predicted positives are actually correct.
If your task cares more about avoiding false alarms, precision matters more.
In the example, three samples (2, 3, and 4) are predicted as positive, and samples 2 and 4 are truly positive, so precision is 2/3.
Accuracy Calculation
accuracy = (TP + TN) / (TP + FP + TN + FN)
This is the proportion of correctly classified samples among all samples.
In the example, there are 7 samples in total, and samples 1, 2, 4, and 6 are classified correctly, so accuracy is 4/7.
However, accuracy can be misleading when classes are highly imbalanced.
In practice, recall and precision often move in different directions. To compare models when both matter, people often use F-measure, usually the F1 score.
f-measure Calculation
The f-measure, or F1 score:
f_measure = 2 * recall * precision / (recall + precision)
F1 combines recall and precision into one value and is useful when both are important.
How to use the confusion matrix in practice
When reading a confusion matrix, do not focus on only one metric. The more useful questions are:
- Is the business problem more sensitive to missed positives or false alarms?
- Are the classes severely imbalanced?
- Do you need to tune a threshold and trade precision against recall?
For example:
- Medical screening often cares more about recall because missing a real positive case can be costly
- Filtering or review pipelines may care more about precision because false alarms create unnecessary downstream work
- In highly imbalanced data, accuracy alone is often not enough, so precision, recall, and F1 should also be checked
Summary
This article introduced one of the most important evaluation tools for classification problems: the confusion matrix. It also explained TP, TN, FP, and FN, and showed how they are used to calculate recall, precision, accuracy, and F1.
In real work, the goal is not just to memorize formulas, but to understand which kind of error matters more in the business context. Once that part is clear, confusion-matrix-based evaluation becomes much easier to interpret.
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/en/932.html
- 版权声明:本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。