Today, while using Python’s Seaborn to plot a heatmap (clustermap), I kept encountering this error. My data seemed perfectly fine, and a Google search didn’t yield any good solutions. After some exploration, I’m sharing the final solution here.
Although the error appears inside Seaborn, the more common root cause is that the DataFrame being passed into plotting has become object dtype instead of a numeric dtype.
1. Generating the DataFrame
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from seaborn import clustermap
import seaborn as sns; sns.set(color_codes=True)
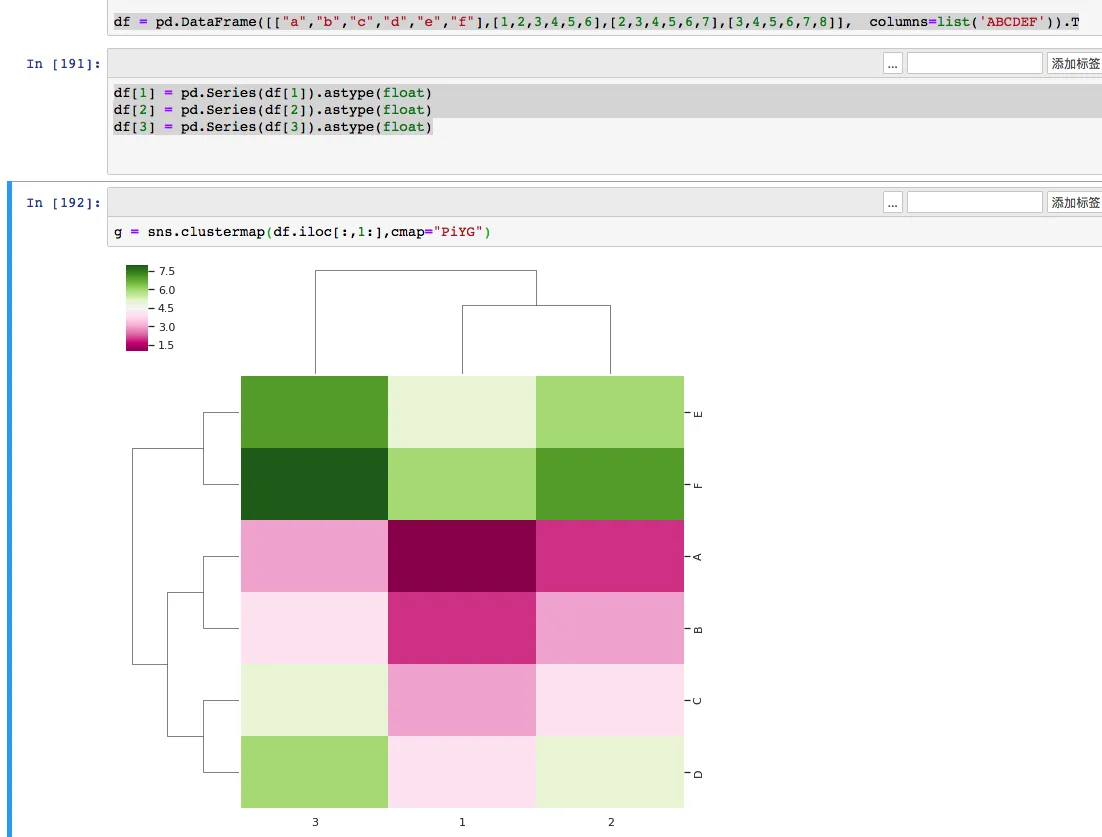
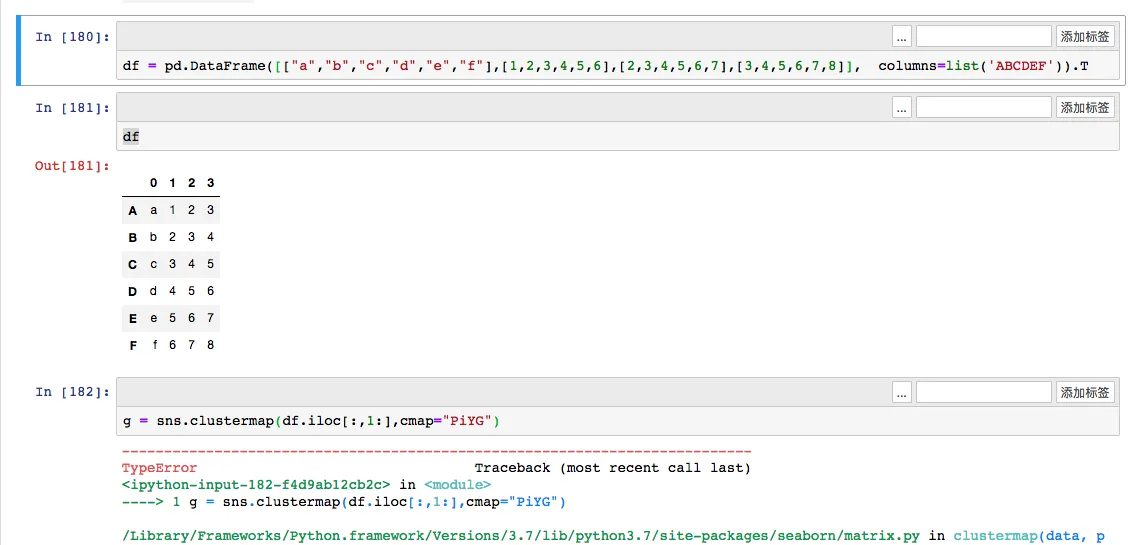
df = pd.DataFrame([["a","b","c","d","e","f"],[1,2,3,4,5,6],[2,3,4,5,6,7],[3,4,5,6,7,8]], columns=list('ABCDEF')).T
df
g = sns.clustermap(df.iloc[:,1:],cmap="PiYG")
After generating and transposing the DataFrame, a TypeError occurs: TypeError: ufunc 'isnan' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule "safe".
……